Sixty-four percent of ML tooling requires either the cloud, a GPU, or more RAM than your average edge device has. This isn’t a feature; it’s a bug for constrained hardware.
And that’s precisely why this post isn’t about some shiny new toy; it’s about Cerberus, a project that forced me to confront a brutal reality: what anomaly detection actually needs on hardware that’s perpetually strapped for resources, and how to achieve it without resorting to opaque black boxes.
Look, when you’re operating in the gilded cage of cloud VMs, the weight of your tooling is an abstraction. You have RAM to burn. Networks hum with the speed of light. Prometheus scrapes endpoints on a LAN that’s as reliable as… well, reliable.
Drop those same assumptions onto a dusty ARM gateway at some remote industrial site, and suddenly everything explodes. The telemetry pipeline starts wrestling the core workload for precious CPU cycles. The collector finds itself stranded by a network connection that simply doesn’t exist. The vaunted ML inference endpoint? It’s miles away in a cloud region the device can’t even dream of reaching.
The tools themselves aren’t the villains here. They were built for a different world. The real problem is the default assumption: treating cloud-native observability as the only option, rather than a conscious choice.
What Does Edge Observability Actually Need?
Once that question was finally wrestled into submission, the answer was surprisingly… small. And remarkably un-fancy.
Did traffic behavior change?
Is something probing unusual ports?
Are protocol patterns different from yesterday?
Is there unexplained traffic acceleration?
Which specific device changed?
This isn’t a distributed tracing headache. It’s a behavioral signal problem. A far more fundamental, and frankly, elegant, set of questions.
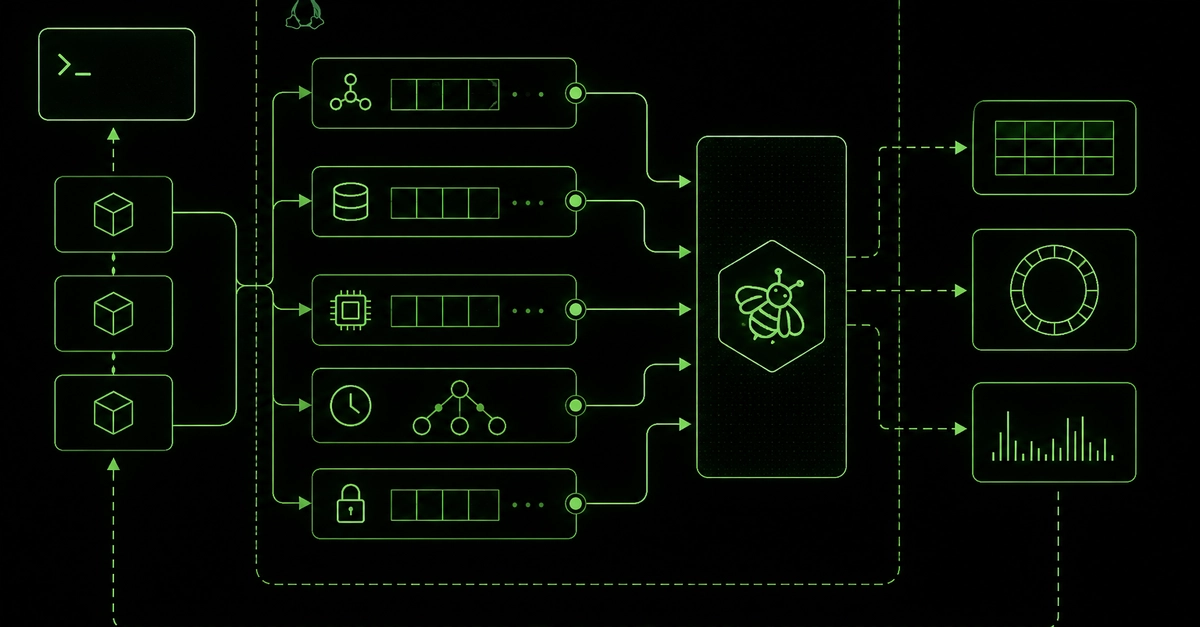
The kernel, bless its heart, already sees everything. Every packet, every connection, every obscure TCP flag – it all waltzes through the network stack before any userspace process even gets a whiff. And eBPF? It’s the VIP pass.
It lets you hang tiny programs directly off that stack, using TC (Traffic Control) or XDP hooks. Forget running tcpdump through a convoluted pipe or slurping full payloads into userspace for tedious inspection. Instead, you write a kernel-side filter. It snatches only the metadata you give a damn about and shoves it into a ring buffer. Clean. Efficient.
For Cerberus, that translates to a neat, tidy 208 bytes per event. A masterpiece of conciseness:
struct network_event {\n__u8 event_type; // ARP / TCP / UDP / DNS / TLS / HTTP / ICMP\n__u32 src_ip;\n__u32 dst_ip;\n__u16 src_port;\n__u16 dst_port;\n__u8 tcp_flags;\n__u8 l7_payload[128]; // first 128 bytes for L7 inspection\n// ...\n};
The kernel filters. The ring buffer delivers. Userspace gets a pristine event stream with almost zero overhead. No bloated payload copies, no parasitic extra processes, no agents gnawing at the CPU the workload desperately needs. On ARM, this isn’t a theoretical improvement; it’s a measurable win.
So, About This ‘ML-Lite’
Let me be crystal clear: I am not an ML engineer. What I’ve cobbled together is better described as applied statistics with a dash of online learning sprinkled on top. I’m calling it ML-Lite because that’s exactly what it is, not because it sounds like a marketing buzzword.
The knee-jerk reaction when confronted with anomaly detection is to immediately reach for a gargantuan neural network or a heavyweight ML runtime. On constrained hardware, that’s a non-starter. It’s a resource black hole, and worse, it obliterates explainability. An operator staring at an alert at 2 AM doesn’t want a fuzzy confidence score; they want to know what the hell changed.
So, this system operates in a lean, mean, three-stage process.
Every 30 seconds, the raw event stream gets mashed into a digestible feature vector:
[packet_rate, dns_rate, tls_rate, syn_rate, entropy, unusual_ports]
This is the “network behavior as numbers” stage. Each window becomes a compact, abstract snapshot of the device’s activities.
As these windows pile up, the system begins to understand “normal” using a trio of surprisingly strong tools:
- Median + MAD (Median Absolute Deviation): This is statistically sound. It’s immune to outliers in a way that simple mean/stddev just isn’t. A single, aberrant traffic spike won’t send your baseline spiraling.
- EWMA (Exponentially Weighted Moving Average): This gives more heft to recent windows, allowing the baseline to adapt slowly. It’s not going to lurch wildly with every minor fluctuation.
- Centroid Distance: This keeps tabs on how far the current feature vector deviates from the historical average. It’s a direct measure of how “unusual” the current state is.
The scoring formula for each feature is elegantly simple:
robust_z = |x - median| / MAD
And entropy, that old chestnut, is computed as:
H(X) = -Σ p(x) log₂ p(x)
Where x represents the distribution of destination ports. Typical traffic hammers a few ports repeatedly, keeping entropy delightfully low. A port scanner, on the other hand, flits across 22, 23, 80, 443, 445, 3389 – its entropy skyrockets. Beautifully simple.
This next part is where the real magic happens – or at least, where the operator gets a fighting chance at understanding what’s going on. The system doesn’t just spit out a number. It tells you which features are driving the anomaly:
WHY?
+ High SYN rate
+ Port entropy spike
+ Traffic acceleration
An operator can actually act on this. Immediately. No cryptic score, just actionable intelligence.
The detection model wasn’t built in a day; it evolved through distinct iterations, each adding complexity without discarding the wisdom of the last:
v1 — Statistical Detection: Median, MAD, thresholds, entropy. It worked, but it was noisy on less predictable IoT networks.
v2 — Adaptive Learning: EWMA, rolling baselines, per-device profiles. This significantly pruned false positives once the baseline had a decent historical context to draw from.
v3 — Isolation Forest: This is unsupervised ML at its finest. Tree isolation, outlier scoring – it doesn’t demand labeled attack data, making it perfect for spotting genuinely novel patterns.
v4 — Tiny Autoencoders: A barely-there autoencoder model, trained on the normal traffic patterns of a specific device. If the reconstruction error goes up, something’s shifted. It’s ML, but so light it barely casts a shadow.
Why Does This Matter for Developers?
The implications here are vast. We’re constantly pushing intelligence to the edge. Think IoT sensors, smart city infrastructure, autonomous vehicles – all running on hardware that would choke on a standard ML framework. This isn’t about replacing cloud-scale ML; it’s about acknowledging that different environments demand different tools.
It’s a return to first principles. Using the kernel’s built-in capabilities, eBPF for surgical precision, and statistical methods that prioritize explainability over opaque complexity. It’s about building tools that are not just performant but understandable.
This approach strips away the fluff. It focuses on what is truly necessary for effective anomaly detection in resource-constrained environments. It’s a stark reminder that sometimes, less truly is more. And that the most powerful tools are often already present, just waiting to be wielded correctly.
The industry’s obsession with ever-larger models often overlooks the fundamental constraints of the hardware they’re meant to run on. This ML-Lite approach is a quiet rebellion against that trend, a pragmatic path forward for edge computing.
🧬 Related Insights
- Read more: AI Code: Good Enough, Never Great?
- Read more: Telegram’s Secret Cloud Storage Unleashed