A single, poorly configured curl flag. A typo. That’s all it took to nearly burn down a database in staging, a stark reminder that “production-like” doesn’t mean “production-tough.” This wasn’t some theoretical exercise; it was a genuine 3 am panic that underscored a fundamental truth: your staging environment needs to be not just a mirror, but a hardened shield against human fallibility. The stakes were high: a new subscription checkout flow for creators, designed to bypass PayPal’s regional blocks, required strong handling of settlement schedules, retries, and event emission. The initial approach—DynamoDB with on-demand capacity—was shot down by finance due to its eventual consistency model, which could lead to costly undercharging discrepancies for up to 12 hours. A ticking time bomb waiting for the wrong trigger.
Here’s the thing about infrastructure gone wild: it rarely starts with malice, but often with indifference to detail. The first attempt at a staging RDS Postgres 14 instance looked innocent enough on paper. Terraform, the darling of IaC, dutifully set up a db.t3.medium instance. Publicly accessible? true. Storage encrypted? false. It sailed through linting because, apparently, AWS tags were the only thing that mattered. Then came the chaos experiment: an intern, aiming for resilience, inadvertently killed the master node. Prometheus dutifully screamed about 503s, but a poorly tuned auto-scaling policy with a 300-second cooldown meant the replacement node took a agonizing 7 minutes to spin up—a delay exacerbated by a 1.2 GB font download for a demo dashboard. The payment service, stubbornly refusing to retry DNS, sent the first 480 requests straight into the abyss.
And Kafka? Oh, staging Kafka. A separate msk.t3.small cluster, meant to test exactly-once semantics, became a disk-space nightmare. The topic auto-created with a retention period of a week (retention.ms=604800000). A single misconfigured producer, and suddenly the cluster was drowning in test messages, its disk usage climbing faster than anyone could monitor. Kafka Manager flashed red, but the on-call team lacked a basic threshold alert for broker disk space dipping below 30 GB. The staging alert router? A Slack webhook spitting messages into #staging-alerts, a channel already choked with 477 muted threads. The crucial notification was lost in the digital noise, scrolled away before anyone registered its SOS.
It became clear: staging wasn’t just broken; it was actively dangerous. The strategy had to shift from mimicking production to actively isolating and controlling the chaos. The goal: a staging environment that was not just disposable, but profoundly observable.
Why a Disposable Staging Environment is Non-Negotiable
The original setup was a house of cards. The reliance on a static Terraform module for RDS, coupled with publicly_accessible=true, created a direct vector for potential damage. The lesson learned was blunt: staging must be ephemeral and self-healing. The new approach embraced Kubernetes and a strong operator pattern. The zalando/postgres-operator now manages an ephemeral Postgres instance, complete with a pgbouncer sidecar, a standby set, and hourly volume snapshots to S3 with SSE-KMS encryption. This means if the cluster does melt down—and in staging, it will—a simple kubectl apply -f restore.yaml brings it back online in under five minutes. Crucially, public accessibility is gone; an AWS PrivateLink endpoint provides secure, controlled access from the Kubernetes cluster, eliminating an entire attack surface. And the terraform apply command itself is now more judicious, using -target flags to prevent route table race conditions that could cascade into wider issues.
The real requirement was: if an engineer turns staging into a dumpster fire at 3 am, nothing outside staging should notice. We also needed to ship a new subscription checkout flow for creators in countries where PayPal blocks transactions.
The payment retry logic also underwent a dramatic overhaul. Shifting from a brittle, legacy PHP helper to a dedicated Go service consuming from an SQS FIFO queue (checkout-payments.fifo) with creator UUID as the message group ID dramatically improves reliability. The queue’s 300-second visibility timeout and a maximum receive count of 3 ensure messages aren’t lost and retries are managed systematically. Crucially, events are published to Kafka only after a successful transaction commit to Postgres. The removal of TTL from the queue guarantees that subscription schedules never evaporate during an outage—a critical business requirement that had been silently at risk.
When Did Infrastructure Become Disposable? The Kubernetes Shift.
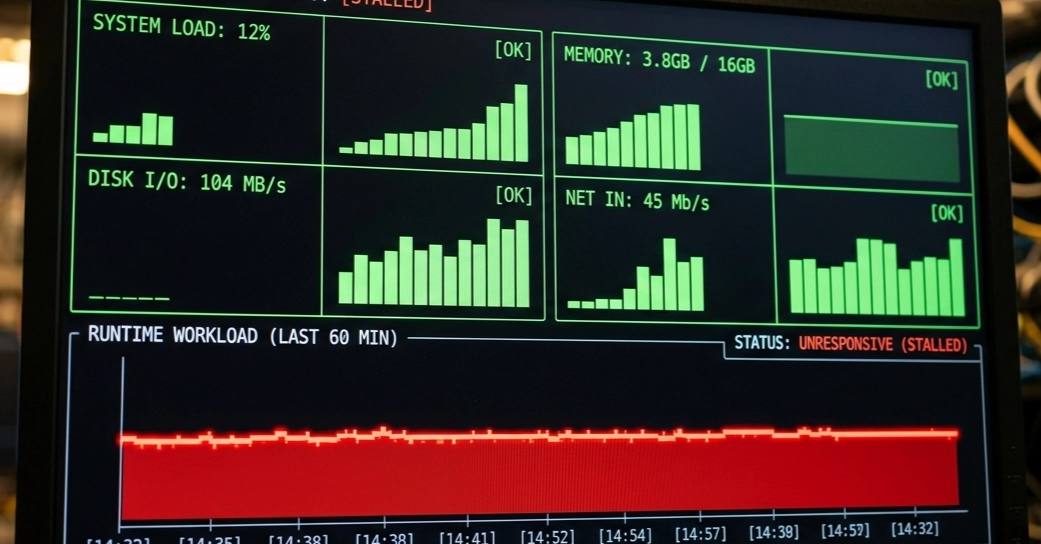
But perhaps the most proactive change is the introduction of a nightly chaos pipeline. This isn’t just testing; it’s active provocation. Scheduled via GitHub Actions at 02:00 UTC, it randomly kills the Postgres primary, injects 500ms latency into the PrivateLink, and simulates failed checkout attempts. The results are posted to a dedicated Slack channel, and more importantly, if the primary doesn’t recover within five minutes, the pipeline directly pages the on-call rotation. This level of automated, aggressive failure testing was previously unthinkable with the old setup. The chaos job even incorporates terraform destroy -target=module.staging_db followed by terraform apply, ensuring a completely fresh, reproducible environment for each test run.
This isn’t just about fixing bugs; it’s about building trust in the system. It’s about recognizing that the “human element” isn’t a bug to be patched, but a force to be managed through intelligent, resilient infrastructure design. The days of “good enough” staging are over. When your database can literally catch fire from a typo, you know it’s time to fundamentally rethink your approach. This company didn’t just rebuild its staging environment; it invested in a more mature engineering culture, one where production-grade reliability starts long before code hits the live servers.
What’s the biggest takeaway? Treat your staging environment as seriously as production, because it’s the last line of defense against cascading failures caused by — well, us. The payment platform, like any critical piece of infrastructure, needs more than just basic observability; it needs intentional resilience and proactive chaos engineering to truly prove its worth. The single point of failure was identified, and a deliberate, observable, and disposable replacement was put in place. This is what a mature DevOps practice looks like.
🧬 Related Insights
- Read more: AI in Auto Repair: The $100M ‘Supplement Packet’ Goldmine
- Read more: AI as a Platform: 6 Apify Actors That Show the Way
Frequently Asked Questions
What does the zalando/postgres-operator do?
The zalando/postgres-operator is a Kubernetes operator that automates the deployment and management of PostgreSQL clusters. It handles tasks like creating primary and replica instances, managing replication, and automating backups and restores.
Why is an SQS FIFO queue important for checkout payments? An SQS FIFO (First-In, First-Out) queue ensures that messages are processed in the exact order they are sent and that each message is delivered exactly once. For payment processing, this prevents issues like duplicate charges or missed transactions, ensuring financial integrity.
Will this new staging setup prevent all database failures? While this new setup significantly enhances resilience and observability in the staging environment, it’s designed to manage and recover from failures, not necessarily prevent every single one. Proactive chaos engineering and automated recovery mechanisms aim to minimize downtime and ensure that issues are detected and addressed rapidly, but the inherent complexity of distributed systems means absolute prevention is often impossible.