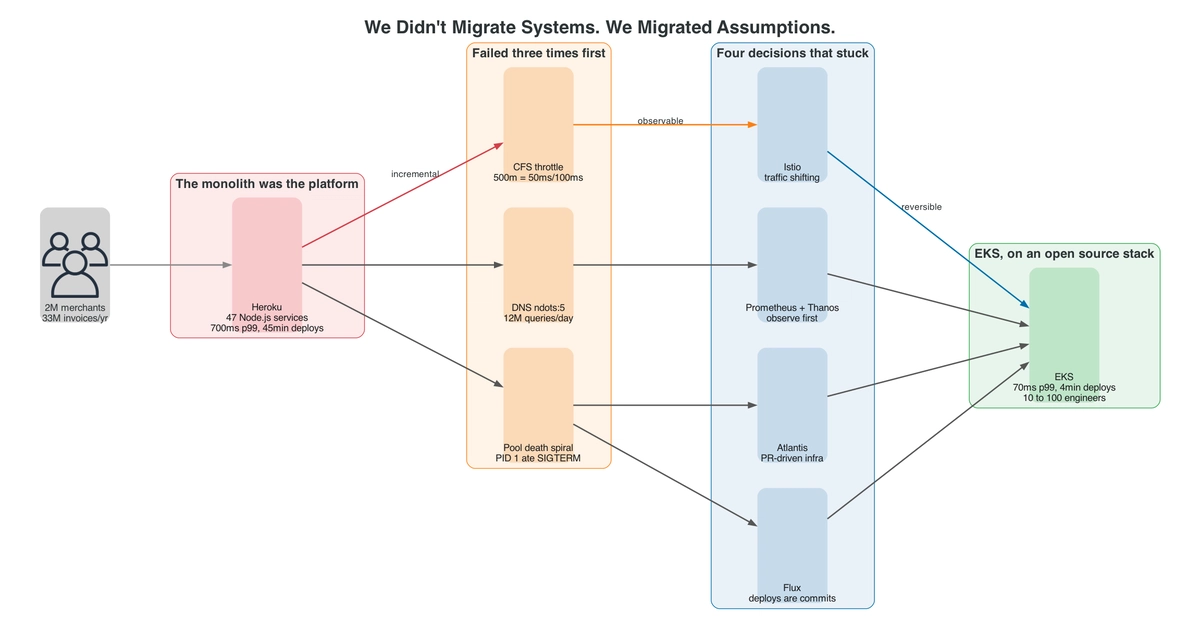
What assumptions are quietly sabotaging your cloud migration? It’s a question few stop to ask. Yet, for one fast-growing invoicing SaaS, it became the difference between project success and a costly rollback. The move wasn’t from Heroku’s managed platform to Amazon EKS for bragging rights; it was a desperate scramble to escape performance ceilings, bloated costs, and glacial deploy times that threatened enterprise SLAs. The stark reality: they didn’t migrate systems. They migrated assumptions.
This isn’t just another cloud migration story. It’s a case study in the hidden pitfalls of Platform-as-a-Service (PaaS) abstraction, culminating in a frank discussion of failures, open-source saviors, and the unvarnished financial impact. The product, serving millions of small businesses and handling tens of millions of invoices annually, relied on a 47-microservice Node.js architecture on Heroku, augmented by SQS and Redis. The platform, however, was the true monolith, and it was Heroku’s invisible hand in orchestrating this platform that proved to be the most significant hurdle.
The pressure points were stark and accumulating: API latency was cratering at 700ms p99, with no discernible levers to pull as Heroku’s dyno scaling hit its limit. Deploys dragged on for 45 minutes or more, a death knell for enterprise-grade SLAs. Observability at the container level was essentially non-existent, forcing guesswork. And the monthly bill? It had quietly surpassed the value delivered, a classic sign of unmanaged sprawl.
The stark choice was clear: remain tethered to Heroku and its limitations, embark on a costly serverless rewrite, opt for raw AWS VMs with velocity sacrifices, or attempt the highest-risk, highest-ceiling path: EKS. They chose EKS.
The Invisible Throttling
The migration to EKS unveiled the first major assumption killer: CPU scheduling. The PDF generation service, a critical component, saw its p99 latency balloon from 800ms to a staggering 9 seconds, all while dashboards deceptively reported a seemingly healthy 35% CPU utilization. The culprit wasn’t a lack of processing power but the Linux CFS (Completely Fair Scheduler) within Kubernetes. EKS enforces CPU limits in precise 100ms slices. A 500m CPU limit translates to only 50ms of CPU time per 100ms period. Node.js, with its libuv worker threads and separate V8 garbage collection, found itself in a constant tug-of-war for those meager 50ms. Operations that took 15ms unthrottled could stretch to 200ms under such contention. The metric that finally told the truth wasn’t CPU utilization but container_cpu_cfs_throttled_periods_total.
Heroku had been hiding that from us by letting dynos burst. The metric that told the truth was
container_cpu_cfs_throttled_periods_total, not CPU utilization.
This revealed a fundamental miscalculation: a CPU limit isn’t just a number; it’s a hard scheduling rule. Heroku’s dynamic bursting masked this underlying reality.
The DNS Amplification Cascade
The second major assumption shattered involved DNS resolution. A subtle difference in the resolv.conf file configuration between Heroku (options ndots:1) and the EKS default (ndots:5) created a ripple effect. With ndots:5, DNS lookups for hostnames with fewer than five dots, like api.stripe.com, triggered multiple search domain queries before attempting the name directly. Multiply this by the 150,000 daily Stripe calls, and you’re looking at 1.5 million unnecessary DNS queries. Across all external integrations, this amounted to around 12 million amplified DNS requests daily, overwhelming CoreDNS. But the disaster wasn’t complete without a second layer of misfortune. A seemingly innocuous npm ci during the Docker build, which produced a lockfile subtly different from Heroku’s slug cache, led to a different version of agentkeepalive. This version recycled connections every 15 seconds instead of the intended 30, effectively doubling the DNS lookup rate before the ndots issue was even diagnosed.
The PID 1 Betrayal
Perhaps the most insidious failure stemmed from a seemingly trivial Dockerfile line: CMD npm start. In its shell form, this command assigns PID 1 to /bin/sh, which, critically, swallows SIGTERM signals. Consequently, the Node.js process never received the shutdown signal, failing to drain its connection pool gracefully. This led to a cascade during a Tuesday deploy: the connection pool exhausted at 450 against a 400 limit within 30 seconds, SIGTERM signals were ignored, and within two minutes, shared Postgres connections on the Heroku side were also depleted. Both environments were down. The fix involved a multi-pronged approach: introducing PgBouncer in transaction mode to cap actual connections at around 80, switching to the exec form CMD ["node", "server.js"] so SIGTERM directly targets the Node process, and implementing a proper SIGTERM handler for graceful draining.
The underlying lesson here is stark: PID 1 is a contract. The shell form breaks that contract, and your application pays the price.
The True Cost of Assumptions
The question that gnaws is: why did standard monitoring miss these issues? CFS throttling was hidden by default behaviors. DNS amplification created a multiplicative problem, not a simple additive one. And the PID 1 issue was a fundamental contract violation that no application-level metric was designed to catch. The migration from Heroku to EKS wasn’t just a technical lift; it was an archaeological dig into the infrastructure assumptions that had been silently governing their operations. Each assumption that proved false was a potential outage, a performance bottleneck, or a cost overrun waiting to happen. The transition, while fraught with peril, ultimately exposed the hidden dependencies and abstract behaviors that PaaS solutions often mask, forcing a confrontation with reality that was both painful and, ultimately, essential for scaling.
🧬 Related Insights
- Read more: Open Source Autonomy: The Unseen Costs of Control
- Read more: Token Refresh Stampede: The Hidden Race Bug Killing Your App’s Auth — Fixed in 40 Lines
Frequently Asked Questions
What are the main differences between Heroku and EKS? Heroku is a fully managed PaaS that abstracts away much of the underlying infrastructure, offering a simpler developer experience. EKS is a managed Kubernetes service on AWS, providing more control and flexibility but requiring a deeper understanding of container orchestration and infrastructure management.
Is migrating from Heroku to EKS always cost-effective? Not necessarily. While EKS can offer significant cost savings at scale due to greater control over resources, the migration itself and the ongoing management require specialized expertise and tooling, which can offset some of the direct infrastructure cost savings. Careful analysis of operational overhead is crucial.
What is PID 1 in a container context? PID 1 is the first process that starts when a container runs. It’s responsible for receiving signals from the container runtime and orchestrating the shutdown of the main application process. The way PID 1 handles signals, particularly SIGTERM, is critical for graceful application termination.