Scalability. It’s the buzzword that makes junior devs’ eyes glaze over and senior engineers sigh wearily. For too long, the common wisdom—drummed into us by conferences and glossy tech blogs—has been that true scale demands microservices, Kubernetes, event-driven architectures, and sprawling cloud infrastructure. The implication? Anything less is amateur hour.
Well, here’s the thing: that narrative is mostly bunk. The actual journey from handling a thousand users to a million is far less glamorous and infinitely more practical. It’s a story of gradual evolution, not a rip-and-replace mandate. It’s about solving actual problems as they arise, not preemptively building a distributed systems Rube Goldberg machine.
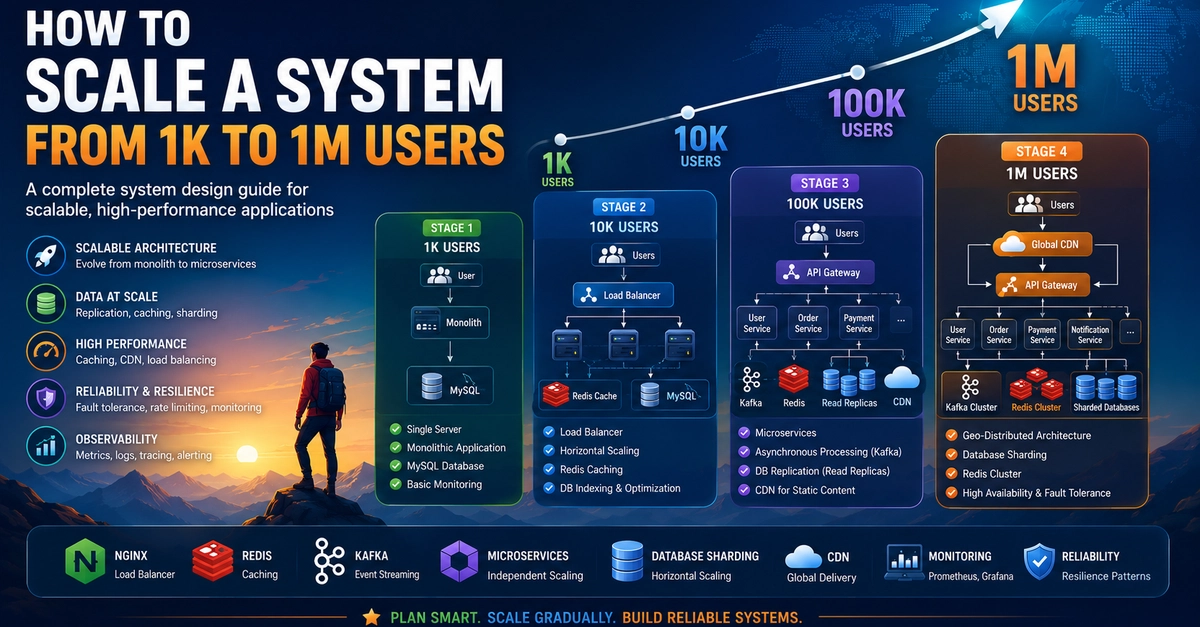
And that’s precisely what this new guide dissects. It pulls back the curtain on how platforms like Netflix and Uber—yes, those giants—started small. They didn’t kick off with a Kafka cluster and a fleet of Kubernetes nodes. They started with a monolith. A single database. Simple deployments.
Why Monoliths Aren’t the Enemy
Think about it. When you’re just getting off the ground, speed matters. You need to ship features. You need to iterate. A monolith, for all its perceived sins, offers faster development cycles, easier debugging (imagine tracing a request across five services before you even have product-market fit), and significantly lower operational overhead. Why complicate things unnecessarily when the goal is just to get something working and find your first paying customers?
This guide emphasizes that the initial stage is about simplicity. It’s about delivering value, not building an infrastructure that could withstand a meteor strike. The complex architectures we often associate with scale are, for most, a premature optimization that can cripple agility.
The Gradual Unfolding of Complexity
So, how do you get from point A to point B? The process looks less like a leap and more like a series of deliberate steps.
First, you layer on the essentials. A load balancer to spread traffic. Caching—often Redis—to take the sting out of database queries. Stateless APIs that make scaling easier. And then, the inevitable moment: database optimization becomes paramount. This is, invariably, the first real bottleneck.
As traffic continues to climb, then you start introducing more advanced concepts. CDNs for static assets. Asynchronous processing. Message queues. Database replication. These are building blocks, each addressing a specific pain point identified through real-world usage, not theoretical elegance.
It’s only when you reach a significant scale—tens of thousands, hundreds of thousands of users—that distributed system concepts truly begin to matter. Microservices architecture. Distributed caching. Database sharding. Reliability engineering. Advanced observability. This is where failures become not just possible, but inevitable. Systems must, by necessity, be designed to recover gracefully.
The most compelling takeaway? Good system design isn’t about constructing the most architecturally complex edifice. It’s about the pragmatic, iterative solving of real bottlenecks, ensuring reliability, and making the right trade-offs at the opportune moment. The simplest system that evolves carefully is often the most scalable.
Most startups do not need microservices early. Monoliths provide: Faster development, Easier debugging, Lower operational complexity.
This isn’t about shunning modern technologies. It’s about understanding their place in the timeline of a product’s growth. Building a microservices empire when you have 100 users is like hiring a SWAT team to guard your lemonade stand. It’s overkill, expensive, and frankly, a bit ridiculous.
What Does This Mean for Developers?
This perspective shift is vital. It means focusing on foundational engineering principles first. Before agonizing over which distributed tracing tool to pick, developers are encouraged to deeply understand database indexing, query optimization, and effective caching strategies. These are the workhorses that carry you through the initial phases of growth. Technologies like Redis aren’t just tools; they’re lifelines that can drastically reduce database load and slash response times, buying you crucial time before more complex architectural changes are needed.
As systems mature, the focus naturally shifts to resilience. Monitoring, retries, circuit breakers, rate limiting, and strong observability become non-negotiable engineering requirements. These aren’t buzzwords; they’re the mechanisms that keep your application from imploding under pressure.
Ultimately, the journey to scale is a marathon, not a sprint. It’s a proof to sound engineering judgment, a deep understanding of trade-offs, and a willingness to let the system’s needs dictate its evolution, rather than imposing a pre-baked architectural dogma.
Is This the End of Microservices?
Absolutely not. Microservices have their place, but their place is typically much later in the lifecycle than many assume. This guide serves as a crucial corrective to the modern tendency to over-engineer from day one. It’s a reminder that the most strong and scalable systems are often the ones that grew organically, addressing problems as they emerged, rather than those built on a foundation of speculative complexity.


