Everyone, and I mean everyone, was buzzing about VRAM. The elephant in the room for running those jaw-droppingly large language models (LLMs) like Mixtral or DeepSeek-V3 locally wasn’t just about having a powerful computer; it was about having a server farm’s worth of memory packed into a desktop. The prevailing wisdom? “Just buy more GPUs.” It felt like the only path forward, a digital arms race where only the deep-pocketed could play. But what if there was a cosmic wink, a clever sidestep that bypasses the entire VRAM dependency? What if the future wasn’t about cramming more silicon into your box, but about re-imagining the very nature of memory itself?
And here’s the thing: that’s precisely what’s happening. It’s like discovering you can build a skyscraper by cleverly distributing the weight, rather than just piling it all on one massive foundation stone. This isn’t just an incremental update; it’s a foundational shift in how we access and utilize computing power, especially for the burgeoning world of AI. The humble NVMe SSD, once relegated to mere storage duty, is now stepping into the spotlight as a first-class citizen in the memory hierarchy.
The breakthrough hinges on a radical re-thinking of how LLMs, particularly those built with Mixture-of-Experts (MoE) architectures, actually function. Think of MoE models as a team of super-specialized geniuses, each an expert in a niche field. When a prompt comes in, the model doesn’t consult every single genius simultaneously. Instead, it intelligently selects just two, maybe three, of the most relevant experts to tackle that specific piece of information. For Mixtral 8x7B, this means that while the entire model might demand a colossal 24GB of weights, at any given moment, you only need a mere 6GB to be active and ready. This is the core insight Apple nudged us towards with their “LLM in a flash” research, and now, it’s landing in the open-source world with a resounding thud.
Enter Micro-Expert-Router. This isn’t just another LLM inference engine; it’s a bold declaration of independence from GPU tyranny. Built from the ground up in Rust – a language synonymous with performance and safety, like a meticulously crafted Swiss watch – it directly streams the necessary expert weights from NVMe SSDs. We’re talking about bypassing the traditional bottlenecks, using low-level magic like io_uring with O_DIRECT, ensuring that data moves with surgical precision. And to top it off? It speaks the language of developers everywhere, offering an OpenAI-compatible HTTP API with that sweet, sweet Server-Sent Events (SSE) streaming.
So, what are the secret ingredients in this digital cauldron?
- SSD-Streamed Expert Loading: This is the heart of the operation. Weights are pulled directly from your NVMe drive, using efficient buffer management and direct I/O to skip unnecessary layers of abstraction. It’s like pulling the exact book you need from a library shelf, rather than having to unbox the entire library first.
- Multi-Tier Expert Cache: It’s not all or nothing. The system intelligently uses your NVMe as a vast, cool-storage area, but also use RAM (with smart Least Recently Used policies and the ability to “pin” critical weights) and, yes, even a little VRAM if you have it, to keep the most frequently accessed experts lightning-fast. It’s a layered defense against latency.
- Quantization Galore: To further shrink the footprint and speed things up, it supports various quantization levels (Q4_0, Q4K, Q8_0) and even the lightning-fast F16 format, intelligently dispatching instructions to your CPU’s AVX2, AVX-512, or AMX extensions. Your CPU isn’t just a passenger anymore; it’s a co-pilot.
- Speculative Decoding Magic: This is where things get really futuristic. The engine uses a “draft engine” to predict future tokens, tying it back to the main model’s embeddings. It’s like having a seasoned chess grandmaster play out a few moves ahead, giving the system a significant speed boost.
- Continuous Batching & More: It’s got the whole modern toolbox: continuous batching for efficient handling of multiple requests, a SafeTensors loader for secure weight management, hot reloading for updates without downtime, a slick TUI dashboard for monitoring, and even a Helm chart for easy deployment in Kubernetes environments.
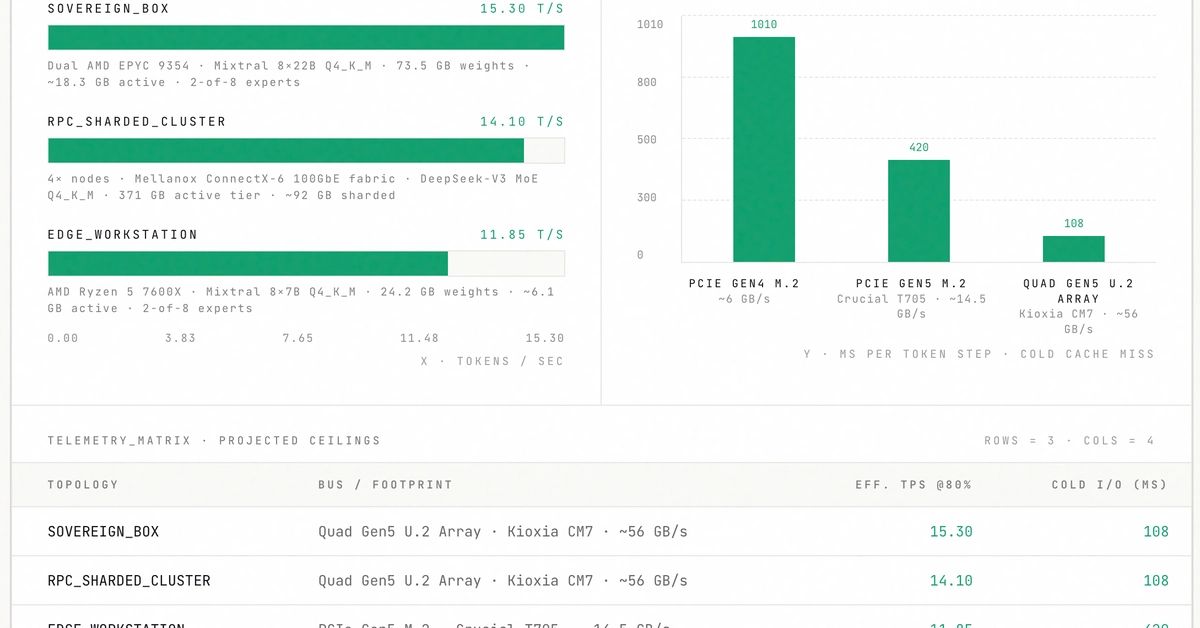
Now, let’s talk numbers, because as the creator honestly admits, full benchmarks are still a pipe dream without the right hardware. The telemetry figures hovering around 11-15 tokens/sec are theoretical maximums, based on ideal cache hit rates and raw NVMe speeds. This isn’t measured performance yet; it’s a tantalizing projection. The cold I/O latency figures – ranging from a zippy 108ms on a bleeding-edge Quad Gen5 U.2 array to a still-respectable 1010ms on a PCIe Gen4 M.2 drive – paint a picture of what’s possible. This is the open-source realization of that “LLM in a flash” concept, an invitation for the community to build upon.
“I don’t have the hardware to run full benchmarks yet. The telemetry figures in the repo (11–15 tokens/sec across edge workstation, sovereign box, and RPC sharded cluster topologies) are theoretical ceilings derived from active weight footprint and raw NVMe sequential bandwidth at 80% cache hit rate — not measured results.”
This is where the real excitement lies. The code is out there. The blueprint is drawn. It’s a call to arms for anyone with the hardware – the NVMe arrays, the capable CPUs – to step up and see if these projections hold true. This is not just about running LLMs; it’s about democratizing access to powerful AI, tearing down the barriers of entry that have kept so many developers and enthusiasts on the sidelines. Imagine a world where your gaming rig, or even a high-end workstation, can serve as a potent AI inference server, no longer tethered to the exorbitant cost of professional GPUs. It’s a vision of AI that’s both accessible and remarkably potent.
Is This the End of the GPU Era for LLMs?
It’s far too early to declare the GPU obsolete. High-end GPUs will always offer unparalleled raw processing power for training and for scenarios where every nanosecond counts and VRAM is plentiful. However, Micro-Expert-Router’s approach fundamentally alters the equation for inference. It shifts the bottleneck from scarce, expensive VRAM to fast, increasingly affordable NVMe storage. This opens up a whole new class of hardware for LLM deployment, including edge devices and workstations that would have been completely out of reach just months ago. It’s not about replacing GPUs, but about creating a powerful, viable, and more accessible alternative for a massive segment of AI workloads. This is an expansion of the AI landscape, not a contraction.
Why Does This Matter for Developers?
For developers, this is a game-changer of monumental proportions. Suddenly, experimenting with, deploying, and even building applications on top of large language models becomes drastically more feasible for a much wider audience. The barrier to entry for local inference plummets. You don’t need to be a millionaire to spin up a powerful LLM. This fosters innovation. It means more diverse voices contributing to the AI ecosystem, more unique applications being built, and a faster overall pace of development. It’s the kind of shift that sparks entire new sub-industries.
🧬 Related Insights
- Read more: Blank Debian VM to Python CI/CD Pipeline: Zero to Hero in 60 Minutes
- Read more: Yumekit: The No-BS Web Component UI Kit Born from a Forgotten Sci-Fi Game
Frequently Asked Questions
What does Micro-Expert-Router actually do? Micro-Expert-Router is a Rust-based inference engine that allows you to run large language models (LLMs) like Mixtral or DeepSeek-V3 by streaming their expert weights directly from NVMe SSDs, significantly reducing the need for large amounts of GPU VRAM.
Will this replace my need for a GPU? For LLM inference, it can dramatically reduce or even eliminate the need for a high-VRAM GPU. For LLM training or other computationally intensive tasks that heavily rely on parallel processing, GPUs will likely remain essential.
How fast is it compared to a GPU? Current projections suggest speeds of 11-15 tokens/sec for certain MoE models with ideal cache hit rates, which is respectable for CPU-based inference but generally slower than high-end GPUs. However, it makes running these models possible on hardware that wouldn’t otherwise support them.