Just how often do we think our beautifully crafted pipelines are rock-solid, only to have a casual comment on a blog post shatter that illusion? For one senior engineer, that moment arrived when a reader pointed out a subtle but devastating bug in a .NET event-driven order pipeline. The issue? A critical race condition where an order could be saved to a database but never published as an event, effectively vanishing into the ether. This isn’t just an academic exercise; it’s a stark reminder of the treacherous currents beneath the surface of seemingly simple systems.
The Ghost in the Machine
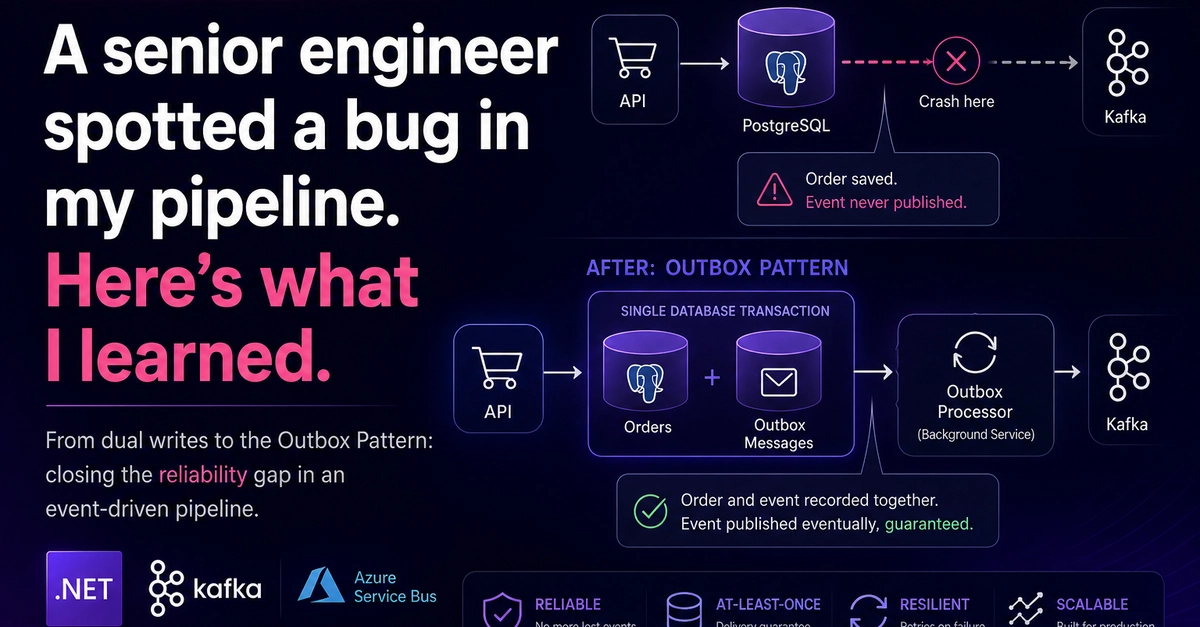
Here’s the core of the problem. The original architecture involved two distinct, uncoordinated operations: first, save the order to PostgreSQL, and second, publish an event to Kafka. Imagine this like a chef plating a Michelin-star dish (saving the order) and then, after the plating is done, deciding to announce the dish to the waiting diners (publishing to Kafka). If, between the plating and the announcement—perhaps the chef trips, the kitchen lights flicker, or a rogue pigeon flies in—the announcement never happens. The beautiful dish is made, but no one knows it exists. The order sits in the database, status ‘Pending,’ but is utterly invisible to the downstream systems meant to process it. At low volumes, this might go unnoticed. In production, with real transactions and customer expectations, it’s a ticking time bomb.
If the API crashes after writing to Postgres but before publishing, you’ve got an order that never gets processed. Have you considered using an outbox pattern or transactional writes to close that gap?
That comment, from Andrew Tan, is the kind of direct, incisive feedback that separates true engineering discourse from the echo chambers of corporate PR. It’s the digital equivalent of a master craftsman spotting a hairline crack in a perfectly polished table.
The Outbox Symphony: Bringing Order to Chaos
The solution, elegantly simple yet profoundly effective, is the outbox pattern. Think of it not as two separate actions anymore, but as a single, atomic declaration. When an order comes in, we don’t just save the order; we also record that this order needs to have an event published about it within the same database transaction. This ‘outbox’ record is essentially a promise, a notification waiting to be fulfilled. A dedicated background service, acting as the conductor of this symphony, then picks up these pending promises from the outbox, publishes the corresponding events to Kafka, and marks them as done. If the publication fails? No problem. The promise remains in the outbox, and the conductor will try again. If the conductor itself has a hiccup? It restarts, picks up where it left off, and ensures every promise is kept.
This isn’t just about fixing a bug; it’s about establishing a single source of truth. The database transaction becomes the ultimate arbiter. Either the order and its accompanying promise to publish are recorded together, or neither happens. There’s no in-between state where one exists without the other. It’s a fundamental principle that underpins the reliability of any distributed system that relies on asynchronous communication.
Code as the Score
Implementing this is remarkably straightforward. The engineer introduced a OutboxMessage model, a humble struct that acts as the record of our promise:
public class OutboxMessage
{
public Guid Id { get; set; } = Guid.NewGuid();
public Guid OrderId { get; set; }
public string EventType { get; set; } = string.Empty;
public string Payload { get; set; } = string.Empty;
public DateTime CreatedAt { get; set; } = DateTime.UtcNow;
public DateTime? ProcessedAt { get; set; }
public bool Processed { get; set; } = false;
public int RetryCount { get; set; } = 0;
public string? Error { get; set; }
}
Then, the controller’s logic transforms. Instead of two separate operations, it’s a single call to SaveChangesAsync() that commits both the order and the outbox message:
public async Task<IActionResult> CreateOrder([FromBody] CreateOrderRequest request)
{
var order = new Order { ... };
var outboxMessage = new OutboxMessage
{
OrderId = order.Id,
EventType = nameof(OrderEventType.OrderCreated),
Payload = JsonSerializer.Serialize(order)
};
db.Orders.Add(order);
db.OutboxMessages.Add(outboxMessage);
await db.SaveChangesAsync(); // one transaction, both or neither
return CreatedAtAction(nameof(GetOrder), new { id = order.Id }, order);
}
Notice how the Kafka publish has been completely removed from the controller. The controller’s job is now solely to ensure the state change is durably recorded, along with the intent to communicate that change.
And the background service, the OutboxProcessorService, becomes the reliable messenger:
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
while (!stoppingToken.IsCancellationRequested)
{
await ProcessOutboxMessagesAsync();
await Task.Delay(TimeSpan.FromSeconds(5), stoppingToken);
}
}
private async Task ProcessOutboxMessagesAsync()
{
var messages = await db.OutboxMessages
.Where(m => !m.Processed && m.RetryCount < 3)
.OrderBy(m => m.CreatedAt)
.ToListAsync();
foreach (var message in messages)
{
try
{
await PublishToKafkaAsync(message);
message.Processed = true;
message.ProcessedAt = DateTime.UtcNow;
}
catch (Exception ex)
{
message.RetryCount++;
message.Error = ex.Message;
}
await db.SaveChangesAsync();
}
}
This loop, polling every five seconds, ensures that even if the publish operation stumbles, the system diligently retries, eventually getting the message out. The log entries paint a clear picture: the order and its outbox message are created together, and then, minutes later, the message is successfully published.
Beyond the Fix: Scaling and Resilience
Andrew Tan, ever the insightful engineer, didn’t stop there. He raised the next set of challenges for a production-grade system. The 5-second polling, while functional, introduces latency and can create database contention, especially at scale. His suggestion of FOR UPDATE SKIP LOCKED is precisely the kind of advanced technique needed to allow multiple OutboxProcessorService instances to run concurrently without fighting over the same records – a crucial step for horizontal scaling. Furthermore, what happens when Kafka is fundamentally unavailable? The current retry-every-5-seconds approach with no backoff is a recipe for overwhelming the system. Introducing a dead-letter queue and alerts for stale outbox messages is the path to true production readiness.
This incident, born from a single comment, illuminates a fundamental truth: the most sophisticated AI systems, the most cutting-edge cloud architectures, still hinge on these bedrock principles of data integrity and reliable message delivery. The outbox pattern isn’t a flashy new technology; it’s a time-tested architectural solution that makes complex distributed systems actually work.
🧬 Related Insights
- Read more: The Website That Throws a Party to Make You Leave: Inside ‘Please. I’m Begging You. Close The Tab’
- Read more: E2E Tests Die in 3 Sprints: The Cache Mental Model That Keeps Them Alive
Frequently Asked Questions
What is the outbox pattern?
The outbox pattern is a design pattern used in distributed systems to ensure that a database record and a message published to an event bus (like Kafka) are processed atomically. It involves writing both the database record and a message to an ‘outbox’ table within the same transaction, guaranteeing consistency.
Why is the outbox pattern important for event-driven architectures?
In event-driven architectures, a failure to publish an event after a state change can lead to inconsistencies and data loss. The outbox pattern ensures that events are reliably published by making the publication an integral part of the transactional commit.
Will the outbox pattern solve all my data synchronization issues?
While the outbox pattern significantly improves reliability by ensuring events are reliably published, it’s part of a larger strategy for data synchronization. Other considerations like idempotency, error handling, and proper monitoring are still essential for a strong system.


