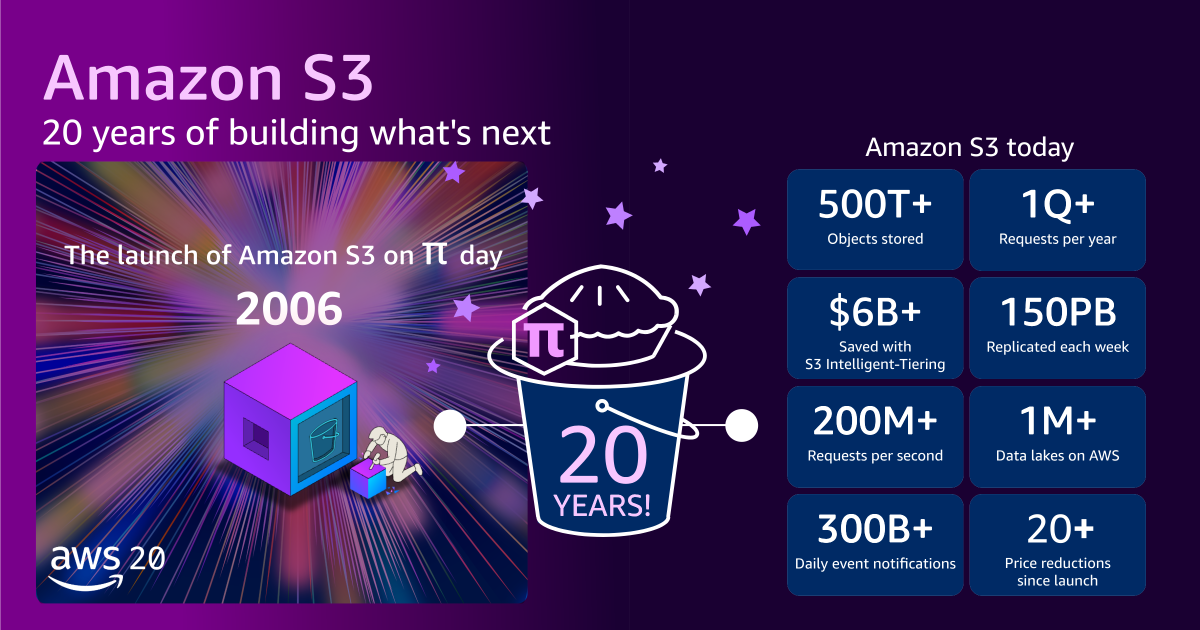
The faint hum of servers in a remote data center, a blink-and-you-miss-it announcement on Amazon’s “What’s New” page—that’s how Amazon S3, or Simple Storage Service, began its life twenty years ago. It wasn’t a flashy product launch; Jeff Barr’s blog post, brief and to the point, was more of a whisper than a shout. Little did anyone know, this quiet debut would fundamentally rewire how we build and scale applications in the digital age.
At its genesis, S3 presented two deceptively simple commands: PUT to store data, GET to retrieve it. But its true genius wasn’t in the commands themselves, but in the profound architectural philosophy they embodied. Amazon offered developers a set of fundamental building blocks, the kind that handle the gnarly, undifferentiated heavy lifting so creators could focus on innovation rather than infrastructure.
This core philosophy has been immutable, guided by five unwavering tenets from day one: security, durability (aiming for an astronomical 11 nines), availability (assuming failure is a constant), performance (scaling without degradation), and elasticity (automatic growth and shrinkage). It’s this commitment to getting the basics profoundly right that allows S3 to become so invisible—so dependable—that most users rarely ponder the colossal engineering effort underpinning it.
From Petabytes to Exabytes: A Scale Almost Unfathomable
Let’s talk scale. When S3 first went live in 2006, it offered a modest petabyte of total storage capacity, distributed across a few dozen racks in three data centers. It handled around 15 Gbps of bandwidth and supported objects up to 5 GB. The price? A hefty 15 cents per gigabyte. Compare that to today: S3 now houses over 500 trillion objects, processes more than 200 million requests per second globally, and manages hundreds of exabytes of data across 39 AWS Regions. Object sizes have ballooned to a colossal 50 TB. If you were to stack all the hard drives currently powering S3, they’d stretch to the International Space Station and back—twice.
And here’s the kicker: while the scale has grown exponentially, the cost has plummeted. Today, you’re paying just over 2 cents per gigabyte, an 85% reduction since its inception. This isn’t just about basic storage; AWS has layered on intelligent tiers, like S3 Intelligent-Tiering, which customers have collectively used to save over $6 billion in storage costs. It’s a masterclass in cost optimization through architectural innovation.
Why Does S3’s API Matter So Much?
Beyond its own impressive growth, S3’s impact resonates through the entire industry. Its API has become a de facto standard, a benchmark that countless storage vendors have adopted or emulated. This widespread compatibility means that the skills developers acquire working with S3 readily transfer to other storage solutions, lowering the barrier to entry and fostering a more interconnected ecosystem.
But perhaps the most astonishing feat, the one that truly underscores the ‘just works’ ethos, is this: code written for S3 in 2006 still works today. Think about that. Over two decades, S3 has undergone massive infrastructure migrations—disk generations replaced, storage systems evolved, and the internal request handling code rewritten countless times. Yet, the fundamental interface, the contract with the developer, has remained inviolate. Your data, stored two decades ago, remains accessible, a proof to a profound commitment to backward compatibility.
The Engineering Engine Under the Hood
So, what magic enables this colossal scale and unwavering stability? It’s not magic; it’s relentless, continuous engineering. Much of the deep technical insight comes from conversations with AWS leaders like Mai-Lan Tomsen Bukovec. At the heart of S3’s legendary durability lies an complex network of microservices. These aren’t just background processes; they are vigilant auditors, constantly inspecting every single byte of data across the entire fleet. When they detect the faintest whisper of degradation, they automatically trigger repair systems. This isn’t just about redundancy; it’s about a proactive, automated system designed to be truly lossless.
This dedication to an almost obsessive level of detail in engineering is what separates S3 from mere storage. It’s an architecture built on the principle that the foundational elements of computing should be so reliable, so scalable, and so unobtrusive that they fade into the background, allowing the real innovation to shine.
A Legacy of Predictability in a Volatile World
Twenty years on, Amazon S3 isn’t just a storage service; it’s a foundational element of the modern internet. Its success is a powerful case study in the value of focusing on core primitives and committing to long-term architectural stability. While the tech world lurches from one trend to the next, S3 stands as a beacon of predictable infrastructure. It’s a reminder that sometimes, the most revolutionary innovations are the ones that simply, quietly, get the basics absolutely, unshakeably right.
🧬 Related Insights
- Read more: Array Flatten in JavaScript: The Quiet Shift from Recursion Nightmares to One-Line Wins
- Read more: AI’s Ad Rebellion: $224B Google Empire Clashes with Ad-Free Rebels
Frequently Asked Questions
What does Amazon S3 actually do? Amazon S3 is a cloud-based object storage service that allows users to store and retrieve any amount of data, from anywhere on the web, through a simple web services interface. It’s designed to be highly scalable, secure, and durable.
Has the S3 API changed over 20 years? No, Amazon S3 has maintained complete API backward compatibility for 20 years. This means applications built on the S3 API in 2006 should still work today without modifications.
Is S3 storage expensive? While pricing varies by region and storage class, S3’s pricing has decreased significantly since its launch. For example, the cost per gigabyte has dropped by approximately 85% since 2006. Additionally, features like S3 Intelligent-Tiering help optimize costs further.