Are you sure your company’s multi-million dollar investment in AI isn’t fundamentally misaligned with its actual goals? It’s a question few are asking, but one with significant financial implications, especially as businesses scramble to imbue their AI models with industry-specific knowledge and use proprietary data. The current dichotomy presented—retrieval-augmented generation (RAG) versus fine-tuning—is the bedrock of this discussion, but the nuances often get lost in corporate marketing.
At its core, the debate hinges on how AI models ingest and utilize data. RAG, a seemingly elegant solution, augments existing language models by pulling in real-time information from external sources—documents, databases, APIs, you name it. The model itself remains unchanged; its accuracy is simply bolstered by fresh, contextually relevant data provided at query time. Think of it as giving a brilliant student access to an up-to-the-minute library. Fine-tuning, on the other hand, is more akin to sending that student to a specialized boot camp. It involves retraining the model on a specific dataset, embedding particular knowledge, styles, or terminology directly into its architecture. This method eschews external data retrieval during inference, relying solely on its baked-in intelligence.
RAG: The Siren Song of Real-Time Data
The appeal of RAG is undeniable, especially for businesses prioritizing agility. Its primary advantage is the ability to access and incorporate current information without the prohibitively expensive and time-consuming process of retraining the entire model. Imagine a financial news bot that can instantly reflect the latest market fluctuations; RAG makes this possible by fetching data on demand. This significantly slashes infrastructure and maintenance costs because companies only need to manage the data retrieval pipeline and its associated embeddings, rather than constantly updating a colossal model. For AI service providers, RAG accelerates deployment cycles, offering clients quicker updates and iterations on their projects.
RAG systems provide traceability of sources for information. This makes organizations more confident about the answers they receive and helps meet the regulatory requirements where applicable.
Beyond speed and cost savings, RAG offers a crucial benefit: transparency. The ability to trace an answer back to its source documents provides a level of confidence and regulatory compliance that purely fine-tuned models often lack. This traceability is not just a nice-to-have; for many industries, it’s a non-negotiable requirement.
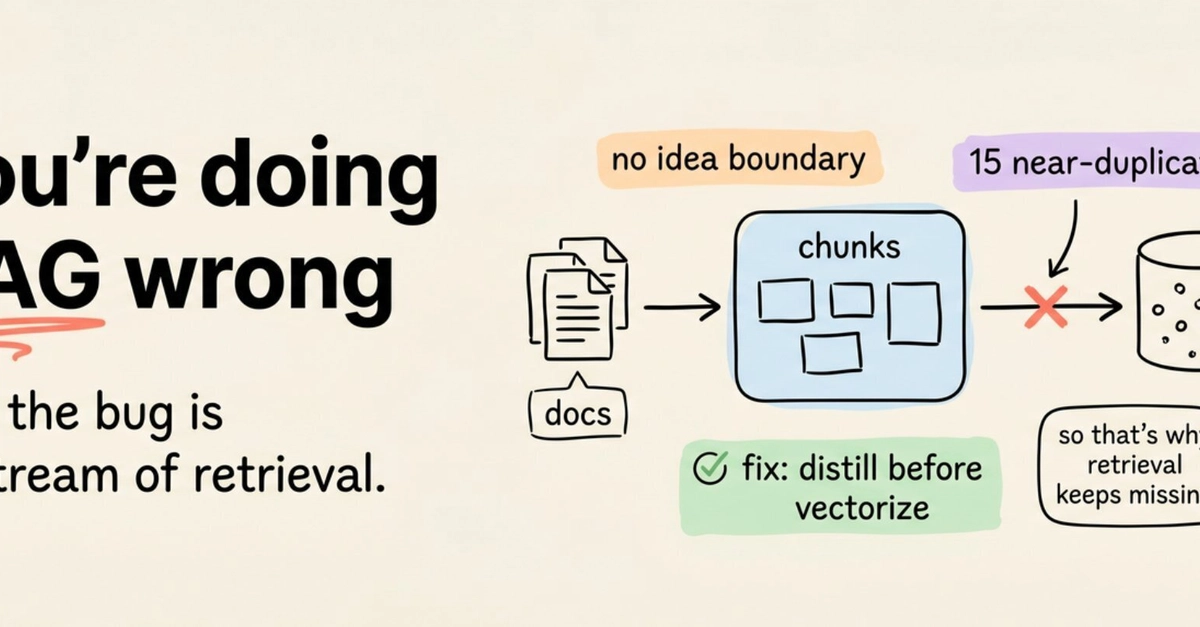
Yet, the RAG approach isn’t without its significant headwinds. The system’s efficacy is intrinsically tied to the quality of its retrieval mechanism. If the embeddings are poor, the search algorithms are imprecise, or the underlying data is unstructured, the model might pull irrelevant, outdated, or incomplete information, leading to responses that are, at best, subpar and, at worst, actively misleading. Furthermore, RAG systems introduce a considerable layer of complexity. Managing vector databases, embedding models, search processes, and complex data pipelines requires a level of specialized expertise and infrastructure that can quickly escalate operational overhead. Many organizations building sophisticated AI solutions find themselves partnering with external AI development services to navigate this labyrinthine architecture.
Fine-Tuning: The Deep Dive into Domain Expertise
Fine-tuning shines brightest when the objective is consistent, deeply ingrained domain-specific behavior. Its superpower lies in behavioral customization. If your brand demands a particular tone of voice, specific industry jargon, or a rigidly defined output format, fine-tuning is the path to achieving that level of stylistic adherence. The model learns to emulate these domain-specific patterns during its training, resulting in more natural, polished responses for repetitive or highly structured tasks without the need for real-time external lookups.
This inherent learning capability also translates to superior response consistency. A well-tuned model can discern and replicate subtle, latent features within its training data, ensuring a predictable and reliable output across applications like customer service, content generation, workflow automation, and AI-enabled SaaS products. Critically, a deeply trained model exhibits less reliance on external searches during inference. This can lead to faster response times and a simpler deployment footprint, as there are fewer moving parts to manage post-training.
However, the path of fine-tuning is paved with considerable expense. It demands high-quality, meticulously curated datasets—often requiring significant human effort for labeling and validation. The computational resources required for such training are immense, necessitating access to powerful GPU clusters. Beyond the initial training, there’s the ongoing burden of model evaluation, careful hyperparameter tuning, and, crucially, continuous retraining to maintain performance as the underlying data landscape or desired behaviors evolve. This isn’t a ‘set it and forget it’ strategy.
The Hidden Cost of the AI Strategy Choice
Here’s the critical insight most analyses miss: the choice between RAG and fine-tuning isn’t just a technical decision; it’s a business strategy masquerading as an engineering problem. Companies often gravitate towards RAG because it seems cheaper and more agile, a quick win for injecting current data. But what they often underestimate is the cost of managing the retrieval system’s complexity and the potential for brittle, inaccurate outputs if retrieval quality falters. Conversely, the allure of a perfectly polished, domain-expert AI via fine-tuning can blind organizations to the upfront and ongoing costs of data acquisition, training infrastructure, and the maintenance of that finely tuned model.
A purely RAG approach is great for factual recall but struggles with nuanced style and consistent persona. A purely fine-tuned model can nail the persona but risks becoming a static artifact, incapable of reflecting real-world shifts without a costly retraining cycle. The ideal scenario, therefore, often involves a hybrid approach—perhaps a fine-tuned model for core persona and style, augmented by RAG for specific, up-to-the-minute factual retrieval. But few vendors are selling this nuanced reality; they’re selling a binary choice. And for the enterprise, making the wrong choice upfront—driven by incomplete understanding or vendor-specific pitches—can lead to inflated operational costs, missed market opportunities, and ultimately, a less effective AI solution than anticipated.
Why Does This Matter for Developers?
For developers, understanding this landscape is paramount. The market is flooded with tools and platforms promising to simplify RAG implementation or streamline fine-tuning. But without grasping the fundamental trade-offs, engineers risk building solutions on shaky foundations. A developer tasked with implementing a RAG system needs to be acutely aware of the importance of vector database selection, embedding model choices, and strong data preprocessing. They’ll spend more time wrestling with search relevance and data freshness than with the core AI model itself.
On the fine-tuning side, the challenge shifts to data engineering and MLOps. The focus is on creating high-quality training sets, managing GPU resources efficiently, and establishing strong pipelines for evaluation and retraining. The code might look cleaner on the surface—just a training script—but the underlying infrastructure and data challenges are immense. The pressure to deliver “intelligent” applications often forces a rushed decision, and developers are left to manage the fallout of a strategy that doesn’t truly fit the problem. The market’s push for easy-to-deploy RAG solutions, while understandable, can mask the inherent complexity of ensuring retrieval quality, a problem that RAG proponents often downplay.
The Future: Beyond the Binary
The current RAG vs. fine-tuning debate feels, frankly, a bit 2023. While these are foundational techniques, the future likely lies in more sophisticated integrations that intelligently combine the strengths of both. We’re already seeing efforts towards adaptive RAG, where retrieval strategies themselves are learned, and techniques that allow for more modular and cost-effective fine-tuning. Ultimately, the “right” strategy isn’t a fixed point but a dynamic equilibrium based on the specific application’s needs for currency, accuracy, consistency, and cost. Businesses and their development teams need to move beyond vendor-driven marketing and engage in a rigorous, data-informed analysis of their actual requirements to avoid building the wrong AI engine.
🧬 Related Insights
- Read more: QodoAI Turns GitHub PRs into AI Brainstorms
- Read more: Valicore: Zero-Dep Runtime Validation That Actually Sticks for TypeScript Teams
Frequently Asked Questions
What is RAG in AI? Retrieval-Augmented Generation (RAG) enhances AI models by enabling them to fetch and utilize real-time information from external data sources to generate more accurate and contextually relevant responses, without altering the core model itself.
What is fine-tuning in AI? Fine-tuning is a process where an AI model is further trained on a specific dataset to adapt its behavior, learn specialized terminology, or adopt a particular style, embedding this knowledge directly into the model’s architecture.
When should I use RAG versus fine-tuning? RAG is ideal when you need AI to access up-to-the-minute information and maintain source traceability, while fine-tuning is best for achieving consistent, domain-specific styles, tones, and terminology ingrained within the model itself. A hybrid approach often offers the most strong solution.