Here’s a number to stop you cold: a new approach claims to cut corpus size by 40x, reduce tokens per query by 3x, and improve vector search relevance by 2.3x. All this, without touching your retrieval algorithm, your reranker, or your embedding model. It’s a radical shift, targeting something upstream that’s been largely ignored.
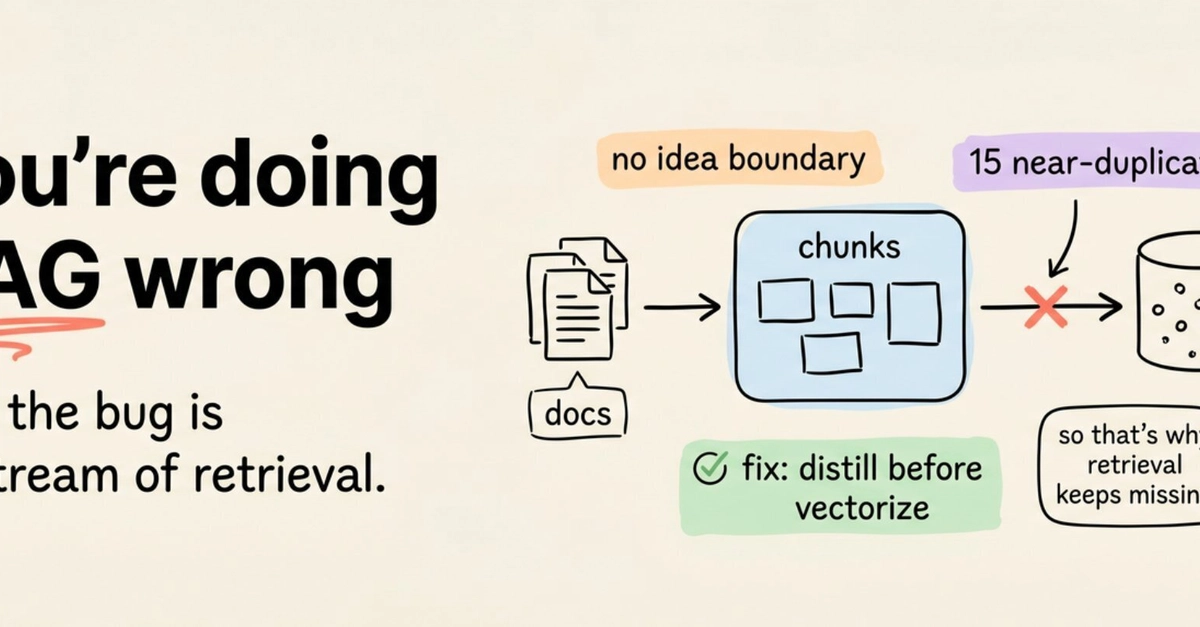
It’s an assumption baked into nearly every Retrieval Augmented Generation (RAG) pipeline: that a chunk of text is the sensible, fundamental unit of knowledge to embed. And that assumption, the article argues, is almost never examined. It’s the root cause of countless retrieval failures that engineers then scramble to fix downstream.
Why the Text Chunk Is Fundamentally Flawed
A chunk of text, by its very nature, is a structurally neutral container. It’s a block of words defined by arbitrary token limits, utterly unaware of anything beyond its own boundaries. It knows nothing about where an idea truly begins or ends. It’s ignorant of which specific version of a document it originates from. It has no clue about access permissions—who is even allowed to see it.
Because it lacks any inherent idea boundaries, the splitter simply cuts wherever the token count dictates. The result? You might retrieve half a table, a conclusion entirely divorced from its supporting argument, or a claim stripped of the very context that gives it validity. The LLM, tasked with synthesizing an answer, has absolutely no way of knowing what’s missing. It’s like handing an architect blueprints for half a building.
And the versioning problem? Equally disastrous. Most enterprise environments are a chaotic soup of documents. Think SharePoint, Confluence, and Git—all hosting dozens of near-identical versions of the same report. Top-K retrieval, bless its heart, often surfaces five copies of the same paragraph, an unfortunate mix of current and deprecated versions. The LLM then endeavors to blend these into a single, confidently wrong answer.
Add to this the absence of metadata attached to the chunk. There’s no natural place to bolt down access control directly within the data itself. Role filters, version state, clearance levels—these vital governance details end up as disparate pieces of logic stitched onto the orchestrator, fundamentally disconnected from the content they’re meant to govern. Frameworks like LangChain, LlamaIndex, and Haystack operate above this mess, orchestrating retrieval from whatever you’ve managed to shove into your vector store. The stark reality is that in most stacks, there’s a yawning void between the document parser and the vector store. It’s in this gap that all three of these problems—context loss, version chaos, and access control disconnect—compound into a retrieval nightmare.
Enter the Question-Answer Packet: A Smarter Unit
The chunk fails because it’s an agnostic, arbitrary container. The elegant fix? Make the unit of knowledge structurally explicit. Instead of embedding a generic window of prose, you embed a focused claim: a single question, its validated answer, and crucially, governance fields presented as a typed schema.
This means one fact, one atomic piece of information, per unit. Nothing more, nothing less. Your queries, after all, are already questions. When your index is structured to store answers to specific questions, the match becomes structural, not merely semantic. You’re no longer hoping that the right paragraph happens to drift to the top of a fuzzy semantic search. You’re directly matching a question to its intended answer.
Blockify, a preprocessing layer from Iternal Technologies, exemplifies this with its IdeaBlock structure. It’s a self-contained unit comprising a question, its validated answer, and typed governance fields like clearance level, version state, and source—all bundled together. This design directly mirrors the natural shape of how users actually interrogate a RAG system: as questions.
The core insight here is profound: when you embed a question-answer packet instead of a mere text window, your embedding vector represents a single, atomic claim. It’s not just a snippet of narrative that happens to contain that claim. This has a demonstrably positive effect on vector geometry. In Blockify’s internal benchmarks, comparing IdeaBlocks against naive text chunks across 17 documents and 298 pages, the average cosine distance from query to the best-matching block was a remarkably low 0.1585 for IdeaBlocks versus a significantly higher 0.3624 for chunks. That’s a 2.29x reduction in retrieval distance, a stark indicator of improved precision.
The key insight: when you embed a question-answer packet instead of a text window, your embedding represents a single atomic claim, not a chunk of narrative that happens to contain it.
The Counterintuitive Truth: Less Data, More Accuracy
It seems paradoxical. Most people anticipate that shrinking the corpus would invariably harm retrieval performance. But that’s precisely where semantic distillation proves its worth. In Blockify’s internal testing, the initial pipeline produced 2,042 raw IdeaBlocks from the source documents. Through iterative deduplication, targeting 80-85% similarity across 3-5 rounds, this set of 2,042 blocks collapsed to a mere 1,200 canonical IdeaBlocks.
The word count plummeted from 88,877 to 44,537. Astonishingly, this distilled dataset outperformed its undistilled counterpart by a significant 13.55% on vector accuracy. The underlying reason for this counterintuitive gain is clear: multiple, near-duplicate copies of the same paragraph create numerous competing vectors clustered in the same region of embedding space. This effectively dilutes the signal, distributing probability mass across all these redundant vectors and lowering the match score for the truly canonical version. By collapsing these duplicates into a single, authoritative block, the signal sharpens dramatically. Your vector index isn’t a storage drive you’re trying to fill; it’s a retrieval surface, and redundancy actively degrades its effectiveness.
The Pipeline: Transforming Documents into IdeaBlocks
This transformative process hinges on a preprocessing pipeline that operates before any data reaches the vector store. Blockify’s pipeline unfolds in seven distinct stages. Each stage is meticulously defined with clear inputs and outputs, ensuring that failures are localized, reproducible, and far easier to diagnose. This modularity is key to maintaining operational integrity.
Stage 1: Scoping
Before a single document is parsed, the system establishes the index hierarchy: Organization > Business Unit > Product > Persona. This hierarchical structure dictates which blocks are assigned to specific access tiers and profoundly shapes how the subsequent deduplication process operates, ensuring contextually relevant filtering from the outset.
Stage 2: Ingestion
Documents arrive in a variety of formats—DOCX, PDF, PPT, PNG/JPG, Markdown, or HTML. The parser then hands off the raw content to the LLM layer. This layer utilizes fine-tuned models like LLaMA 3, QWEN 3.5, Gemma 4, and other custom foundation model variants. Their task is to convert these raw, unstructured chunks into draft IdeaBlocks. Each draft IdeaBlock comprises a single critical question and its validated answer.


