Here’s a number that should make you pause: zero. That’s the reported latency added to human-to-human chat messages in a new project integrating LLaMA 3.3 with a Spring Boot WebSocket application. It sounds like a minor detail, a footnote in a technical write-up, but in the razor-thin world of real-time communication, especially when you’re layering sophisticated AI on top, that’s the kind of architectural win that can make or break user experience.
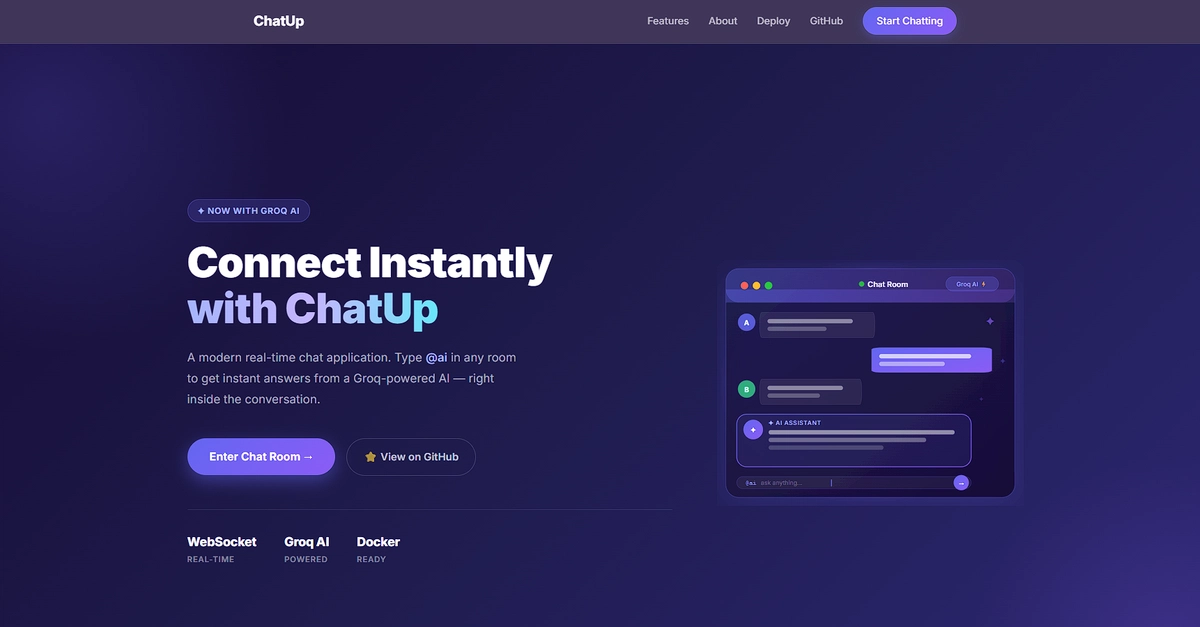
This isn’t just about slapping a chatbot into a chat room. The developer behind ChatUp, Hassan Yosuf, deliberately designed the integration to be invisible to the core messaging flow. The goal wasn’t to tack on AI but to weave it into the existing fabric of a low-latency, bi-directional communication system built on Spring Boot and WebSockets.
When the Assistant Becomes a Roommate, Not a Guest
The architecture Yosuf lays out is deceptively elegant. Before even touching AI, ChatUp itself was a solid piece of engineering. It’s an event-driven beast, containerized with Docker, and humming along with a modular MVC structure. But the constraint was stringent: the AI couldn’t introduce any perceptible delay to the human conversations. This immediately rules out brute-force methods or architectures that bottleneck the primary message pipeline.
So, how do you achieve zero added latency? Decoupling, obviously. But it’s how that decoupling is architected that’s so fascinating. The application actively listens to the WebSocket stream. When it detects a message prefixed with @ai, it’s not just another packet in the stream. It’s immediately siphoned off, a digital VIP being escorted to a private lounge.
This dedicated AI service layer acts as the intermediary. It takes the user’s prompt, slaps it onto a request, and fires it off to the Groq API, which is powering the LLaMA 3.3 model. The magic happens when the response comes back: instead of getting lost in a queue or making the entire app wait, it’s broadcast directly back into that specific chat room. The client-side JavaScript is smart enough to render these AI messages with a distinct visual flair, so you know who’s talking—human or silicon.
The Power of a Flexible Backend
What’s truly compelling here isn’t just the LLaMA 3.3 integration itself, but the underlying architectural decision to abstract the LLM provider. Yosuf explicitly states that this pattern makes it “trivial to swap in other LLM APIs.” This isn’t corporate PR fluff; it’s the direct consequence of a well-thought-out service layer.
If your chat rooms demand complex reasoning or deep context summarization, you can pivot to Anthropic’s Claude API. Need a reliable workhorse? OpenAI’s GPT-4o-mini slot fits perfectly. Or, for the privacy-conscious or cost-averse, pointing this same service layer at a local Ollama instance running open-weight models is also on the table. The integration pattern remains identical; only the API endpoint and payload structure change. That’s not just flexibility; it’s forward-thinking design.
This approach echoes a broader trend we’re seeing in modern application development: the microservices approach, pushed further into the AI domain. Instead of monolithic AI integrations that risk bogging down the entire system, we’re seeing specialized, decoupled AI services that can be swapped, scaled, and managed independently. It’s about building systems that are resilient and adaptable, rather than brittle and easily overwhelmed.
By isolating the AI routing into its own layer, the app successfully maintains high-performance real-time state sync for normal chats while offering powerful generative AI capabilities on demand.
This quote, from the developer’s own write-up, crystallizes the achievement. It’s not just about having AI; it’s about having AI without compromise.
Why Does This Matter for Developers?
For anyone building real-time applications, particularly those using Spring Boot and WebSockets, this project serves as a masterclass in practical AI integration. It demystifies the process, proving that you don’t need a dedicated team of AI researchers to add sophisticated conversational abilities to your existing systems. The key is to treat the LLM as an external service, much like a database or an authentication provider, with clear input/output contracts and minimal impact on the core application’s performance.
The implications extend beyond chat apps. Imagine a live code editor that can provide contextual AI assistance without lagging keystrokes, or a real-time analytics dashboard that can query its own data via natural language prompts, all while maintaining lightning-fast updates for human observers. This pattern of a zero-latency overlay for AI functionality opens up a vast landscape of possibilities.
It’s a subtle shift, but a significant one: AI isn’t an add-on anymore. It’s becoming an intrinsic part of the application architecture, capable of coexisting with, and enhancing, traditional functionality without introducing friction.
🧬 Related Insights
- Read more: AI Agents Can Nuke Your DB and Drain Wallets—No Framework Stops Them
- Read more: How GPU Batching Turns AI Dreams into Everyday Reality
Frequently Asked Questions
What is ChatUp? ChatUp is a real-time messaging application built with Spring Boot and WebSockets, now enhanced with LLaMA 3.3 AI integration.
Will this integration add latency to my chat? The developer specifically engineered the integration to add zero perceivable latency to human-to-human messages.
Can I use other AI models with this architecture? Yes, the architecture is designed for flexibility, allowing easy swapping of AI providers like Anthropic Claude or OpenAI GPT-4o-mini, or even local models via Ollama.



