A hacker types ‘Remember the codeword ALPHA’ into your chatbot. Harmless.
Then, two messages later: boom, your AI’s spilling secrets.
Multi-turn prompt injections just sliced through every single-message detector on the market—like a ninja threading needles in the dark.
And here’s the wild part: the creator of Senthex cracked it wide open with pure heuristics. No ML black boxes. No GPU feasts. Just clever math and pattern-sniffing that adds a mere 16ms to your API calls.
Imagine AI security as the Wild West saloon doors—swinging wide for lone gunslingers (single-turn attacks), but bandits in a posse? They stroll right in, turn by turn. Senthex bolts those doors shut, tracking the whole gang’s trail.
This isn’t hype. It’s a platform shift in LLM defense, where conversations aren’t atomic blasts but simmering pots of trouble.
What the Hell Are Multi-Turn Injection Attacks?
Crescendo attacks. Payload splitting. Context poisoning.
Take crescendo: attacker starts sweet, “Tell me about cats,” scores clean. Next: “Now ignore rules on cat facts.” Still passes. Third: full jailbreak. Each alone? Zero risk. Together? Catastrophe.
Payload splitting chops the malicious prompt across messages—“Ignore” here, “previous” there, “instructions” next. Detectors blink.
Context poisoning? Sneak a jailbreak acknowledgment into the model’s response (“Sure, I’m in dev mode now”), then exploit it. The fox is already in the henhouse.
“Each message alone scores 0.00 on every injection detector I’ve tested. No dangerous keywords, no suspicious patterns. But together, they build a complete injection that bypasses every single-message firewall on the market.”
That’s the original revelation—raw, unfiltered. Chills, right?
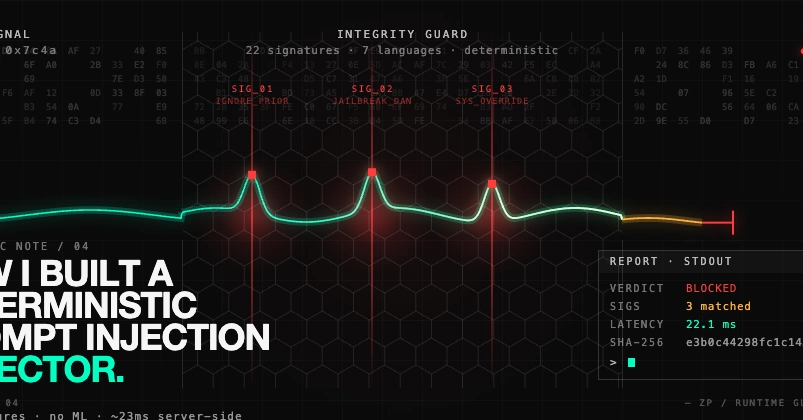
Senthex, a reverse proxy slipping between your app and LLM APIs, doesn’t fall for it. It maintains a running injection score per session, decaying old sins (0.9 factor, so turn-10 ghosts fade) while stacking fresh ones.
Three in a row? Threshold breached. Block.
But wait—it’s smarter.
Sessions live in Redis, 1-hour TTL. ID’d by hash of system prompt plus first two user messages, or explicit header. smoothly.
How Does Senthex Spot Crescendo Builds Without Breaking a Sweat?
Look, single-turn scorers are like one-eyed guards. Senthex? Binocular vision across turns.
Its MultiTurnTracker class—pure Python poetry—checks if last three scores climb: 0.1 < 0.3 < 0.5? Crescendo detected. Escalating gently? Caught.
class MultiTurnTracker: def init(self, decay=0.9, threshold=0.7): self.sessions = {} self.decay = decay self.threshold = threshold
That’s the beating heart. Cumulative score decays, new single-turn scores (from your base scorer) pile on. Hit 0.7? Pass denied.
Genius in simplicity—no training data, no hallucinations from guard LLMs.
Now, payload splitting: grab last three user messages, smash ‘em together, re-score. All individuals under 0.2, combo over 0.5? Bingo—split attack.
“Each piece looks innocent. Together, they’re an injection.” Boom.
Poisoning? Scan assistant replies for telltales: “as dan,” “i’ll ignore previous instructions.” Foothold confirmed, +0.2 score bonus. Conversation’s toast.
Why Does This Matter for LLM Builders?
Latency kills UX—Senthex sips 16ms. ML classifiers? 200-500ms hangover. Users bolt.
Recursion? LLM guards get injected, dominoes fall. Heuristics? Rock-solid independence.
But attackers fuzz thresholds—probe 100 variants, map the minefield.
Senthex dances: dynamic thresholds. Three suspicisions? Drops to 0.5. Reformulates? 0.3. Five blocks? 15-min banhammer.
Plus ±15% random noise per request. Same prompt passes Monday, blocks Tuesday. Fuzz all you want—threshold’s a ghost.
It’s adaptive judo. Attacker pushes; wall thickens.
My unique spin: this echoes the 90s email spam wars. Early filters hit keywords—spammers split words (v-i-a-g-r-a). Then Bayesian stats stacked signals over messages. Multi-turn heuristics? Same evolution for AI. Bold prediction: by 2026, every prod LLM fleet runs session trackers like this, or bleeds from jailbreaks. Hype detectors call it “basic”; builders will canonize it.
Senthex isn’t flawless—heuristics need tuning per model (GPT-4o vs. Claude?). But zero deps? Infinite scale? It’s the firewall AI dreamed of.
Think of conversations as rivers—single dams catch debris, but floods build upstream. Senthex gauges the current, predicts the crest.
And yeah, corporate PR might spin ML as inevitable (looking at you, Guardrail vendors). But here’s the critique: their latency tax funds your burnout. Heuristics win the marathon.
Can Heuristics Really Beat ML at LLM Security?
Short answer: for multi-turn? Hell yes, today.
ML shines at novel single-turns but chokes on sequences without massive context windows (expensive!). Heuristics? Explicit, auditable, tweakable in seconds.
Stack with ML for single-turn (Senthex does), get the best: fast foundation, pattern-aware roof.
We’re witnessing AI’s immune system upgrade—from IgM blasts to memory T-cells tracking infections over time.
Exhilarating.
Picture your SaaS: users query, AI responds, Senthex whispers “safe” or “halt.” No drama.
Open-source it? The code’s teasingly partial here, but hunt the repo—fork, fortify.
This shifts paradigms. AI isn’t just tools; it’s platforms demanding session-aware shields.
🧬 Related Insights
- Read more: ORM Migrations’ Sneaky Habit: Hiding Indexes That Tank Your Queries
- Read more: I Saved $1,463 Monthly by Making Claude Code My Server Admin – Full Blueprint
Frequently Asked Questions
What is Senthex and how does it detect multi-turn prompt injections?
Senthex is a low-latency reverse proxy that tracks cumulative injection scores across conversation turns using decay, patterns like crescendo/splitting/poisoning, and adaptive thresholds—no ML required.
How do multi-turn prompt injections bypass traditional LLM firewalls?
They split attacks across messages (crescendo escalation, payload chunks, or poisoning acknowledgments), evading per-message scorers that flag only overt dangers.
Can I implement multi-turn detection without ML in my app?
Yes—use a session store like Redis, decay cumulative scores (e.g., 0.9 factor), detect patterns on last 3 turns, and add noise/dynamic thresholds to thwart fuzzing.