Did you know that some of the biggest names in cloud computing – AWS, Google, and Cloudflare – are actively moving away from the standard container runtime, runc? It’s not a niche experiment; it’s a strategic shift driven by hard data on security, latency, and cost. For years, the conversation around containers has been dominated by Docker and its underlying runtime, runc. It’s the default, the workhorse, and for many, the assumed standard. But what if that default is actively hindering your ability to achieve the security guarantees or performance profiles demanded by modern, high-stakes applications? The stark reality is that major cloud providers have already made their calculations and diversified. This isn’t about finding a slightly faster way to spin up a web server; it’s about fundamentally rethinking the isolation models that underpin our digital infrastructure.
The Unspoken Truth: runc Isn’t the Only Game in Town
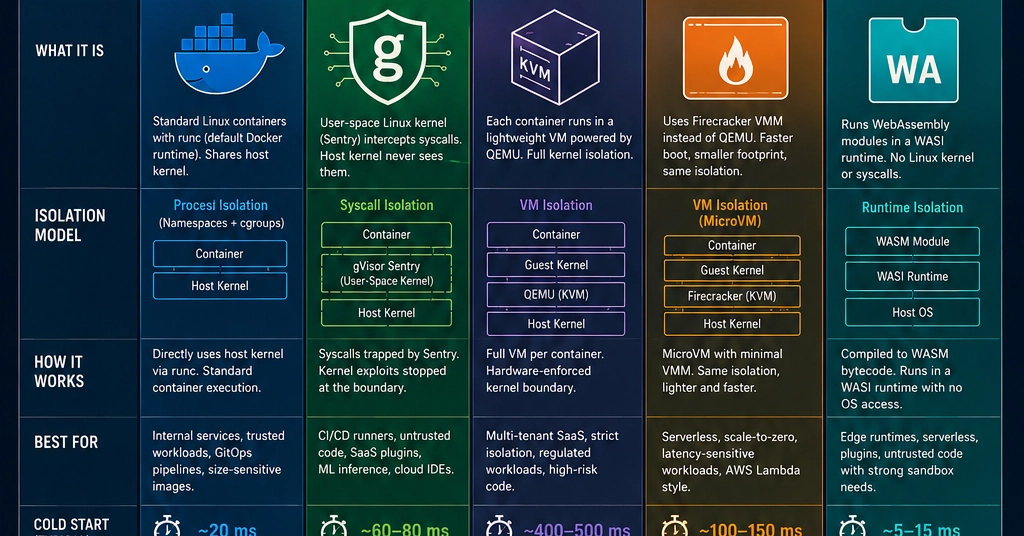
The sheer ubiquity of runc has, perhaps, lulled many into a sense of complacency. It’s so deeply embedded in the tooling and workflows that questioning its supremacy feels almost heretical. Yet, the evidence is mounting. Companies like AWS, with their Lambda functions, don’t just slap your code into a runc-managed container. They opt for Firecracker microVMs. Fly.io, a rising star in the platform-as-a-service space, use a Firecracker fork for its Machines. Google, in its multi-tenant GKE environments, turns to gVisor. And Cloudflare Workers? They’re often running on WebAssembly (WASM).
These aren’t arbitrary choices. They stem from a calculated assessment of threat models, latency sensitivity, and operational efficiency. The default isolation provided by runc, which shares the host kernel, presents a specific set of risks that these organizations have decided are unacceptable for their specific use cases. It’s a compelling data point: if the hyperscalers are diversifying their runtime strategy, it’s time for the rest of us to pay attention.
Benchmarking the Contenders: What Do the Numbers Say?
To cut through the hype and understand the practical implications, a recent deep-dive into five distinct container runtimes is illuminating. The experiment involved a simple 3MB Go HTTP server, tested across runc/distroless, gVisor, Kata Containers (with QEMU and Firecracker), and WASM/WASI. The core finding? The underlying application often remains the same, meaning the switch is largely an --runtime=X flag away. The real differentiators emerge in cold-start times and resource consumption.
Cold-start performance, a critical factor for serverless and highly elastic workloads, shows a dramatic range. runc clocks in around 20ms, a blistering pace. gVisor sits in the middle, with Kata/QEMU pushing towards 500ms, and Firecracker landing between them at approximately 125ms. Shockingly, steady-state request latency overhead across most of these runtimes is negligible. The key takeaway here isn’t about raw throughput; it’s about the trade-offs in memory footprint and compatibility.
The default Docker runtime (
runc) but with a distroless base image. No shell, no package manager, noapt, nocurl. Just the Go binary and CA certificates. The image comes out at 3.0 MB. Alpine would be ~18 MB. Ubuntu ~80 MB.
This highlights a crucial point: image size itself is a critical security and efficiency vector. distroless images, stripping away unnecessary tools, drastically reduce the attack surface. It’s not about preventing a breach entirely – an unlikely feat – but about making the post-breach environment so inhospitable that an attacker’s foothold is severely limited.
The Distroless Advantage: Smaller Footprint, Tighter Security
Let’s linger on this distroless concept for a moment. It’s not a runtime in itself, but a way of building container images that plays exceptionally well with various runtimes. The stark contrast in image sizes – 3MB for a Go binary with distroless versus 18MB for Alpine or a whopping 80MB for Ubuntu – is a data point that cannot be ignored. This reduction isn’t just about saving disk space; it’s a direct correlation to a reduced attack surface. Less code means fewer potential vulnerabilities. It’s a fundamental security principle applied at the image level, complementing the isolation provided by different runtimes.
This approach is particularly compelling for internal microservices within trusted, single-tenant clusters, and absolutely essential for GitOps pipelines where you control every artifact. It’s the baseline security posture every team should be striving for before even considering the added overhead of more complex runtimes.
gVisor: The User-Space Kernel Gambit
Google’s gVisor introduces a unique isolation mechanism: a user-space kernel, dubbed Sentry, written in Go. Every system call (syscall) your container makes is funneled through Sentry before reaching the host kernel. This creates a critical buffer. A kernel exploit within your container simply doesn’t have a direct path to the host. Initially reliant on ptrace for syscall interception, the newer Systrap mode, leveraging seccomp, offers a significant performance uplift – roughly double. This addresses a major criticism of earlier gVisor versions.
While gVisor isn’t a full Virtual Machine, it provides a strong sandbox. A kernel exploit is contained. However, it’s important to understand its threat model: syscall isolation. It’s not a hard boundary in the same way a VM is. Memory, CPU, and certain network layers are still shared at some level with the host. Its strength lies in preventing kernel-level breakouts.
Where does gVisor shine? The most prominent use case is CI/CD runners. Think self-hosted GitHub Actions, GitLab runners, or Buildkite agents that execute arbitrary user pipelines. You don’t control the user’s code; gVisor significantly limits the potential blast radius of a compromised runner. ML inference APIs, where users might submit custom model weights or code, are another prime candidate. SaaS platforms allowing custom logic execution – Zapier-style automations, Retool actions, webhook processors – also benefit immensely from this enhanced sandbox. And for cloud IDE backends, like GitHub Codespaces, gVisor ensures each user’s environment is securely isolated.
Kata Containers: The VM-Based Fortress
Kata Containers takes a decidedly different approach, spinning up a lightweight QEMU MicroVM for each container. This means your application runs within its own dedicated Linux instance, complete with its own kernel. From the perspective of the container orchestration system (like containerd), it appears as an OCI runtime. But internally, it’s a full-blown virtual machine. The host system sees a qemu-system-x86_64 process, and the isolation is genuine. The container image is mounted via virtiofs, and crucially, the kernel boundary is absolute.
Kata Containers boots a lightweight QEMU MicroVM per container. Your app runs inside a VM with its own kernel. containerd sees an OCI runtime; your process sees a dedicated Linux instance.
This is the key differentiator: Kata/QEMU offers a true hardware-enforced boundary. Unlike gVisor’s software-based syscall isolation, Kata provides a VM-level separation. If your primary concern is ensuring that a kernel exploit within the container has absolutely no possibility of affecting the host kernel, then Kata is the answer. It’s the most strong isolation model among the tested runtimes.
Firecracker: The AWS MicroVM Standard
While Kata uses QEMU, AWS’s Firecracker offers a specialized, optimized approach to microVMs. It’s designed for extreme speed and minimal resource overhead, making it ideal for serverless workloads. The core benefit is the VM isolation, similar to Kata, but with a focus on efficiency. It splits the difference in cold-start times between the fast runc and the slower Kata/QEMU, offering a compelling balance for many production scenarios. Its integration into AWS Lambda and Fly.io’s platform speaks volumes about its production readiness and performance characteristics.
WASM: The Next Frontier or a Niche Tool?
WebAssembly (WASM) represents a paradigm shift. Instead of running a compiled binary in a Linux environment, you’re targeting a different execution environment entirely. This means compiling your application specifically for WASM. The isolation is inherent to the WASM sandbox itself, offering a different kind of security model. However, the primary hurdle is the compilation target. It’s not a drop-in replacement for existing containerized applications; it requires a re-architecting or recompilation of your codebase. For new applications or services designed with this in mind, WASM offers extreme portability and a strong security model, but for many existing containerized workloads, it remains a more distant proposition.
Why Does This Matter for Developers and Operations?
The implications here are vast. For developers, it means understanding that the docker run command is merely an abstraction layer. The choice of runtime has tangible impacts on security posture, performance, and even the types of applications you can confidently deploy. For operations teams and platform engineers, it’s about moving beyond the default and making informed decisions based on workload requirements. Are you running untrusted code? Kata or gVisor are strong contenders. Do you need rapid scaling with minimal latency for many short-lived tasks? Firecracker or even optimized runc with distroless images might suffice. Ignoring these advancements isn’t just missing out on better performance; it’s potentially leaving your infrastructure exposed to risks that are now demonstrably addressable with alternative technologies.
🧬 Related Insights
- Read more: AI Cold Starts: Is Cloud Run Actually Sane? [20s Latency]
- Read more: Resend Email Script: A Manual Trigger for Notifications
Frequently Asked Questions
What is runc?
runc is the low-level, open-source container runtime that powers Docker and Kubernetes. It’s responsible for creating and running containers based on the OCI (Open Container Initiative) specification, primarily by interacting with Linux kernel features like namespaces and cgroups to isolate processes.
Will these new runtimes replace Docker?
Not exactly. Docker, as a platform, provides a higher-level abstraction. These alternative runtimes are often pluggable into container runtimes like containerd, which Docker uses. So, you can often use Docker’s tooling while specifying a different runtime like gVisor or Kata.
Is WASM a direct competitor to container runtimes?
In some ways, yes, but it’s a different approach. WASM is an execution target, whereas container runtimes manage isolated Linux processes. WASM offers strong sandboxing and portability but typically requires applications to be compiled for it, unlike traditional container images that run on a Linux OS kernel.