Local LLMs Are Eating Your Hardware Alive: Track Costs and Rate Limit Before It's Too Late
Everyone thought local LLMs meant free AI magic. Reality? They're resource hogs that crash your rig without strict controls. Here's how to track costs and slam on the brakes.

⚡ Key Takeaways
- Local LLMs guzzle VRAM via KV cache — track tokens religiously to avoid OOM disasters.
- Token Bucket rate limiting handles bursts while protecting hardware; superior to crude RPM caps.
- Optimization like batching and re-ranking turns prototypes into production beasts — but NVIDIA still wins.
Worth sharing?
Get the best Developer Tools stories of the week in your inbox — no noise, no spam.
Originally reported by dev.to
Related Stories

Cloud & Infrastructure
Gemma 4 on Ollama: I Pushed All Four Sizes to Their Limits on Crappy Hardware
Open Source
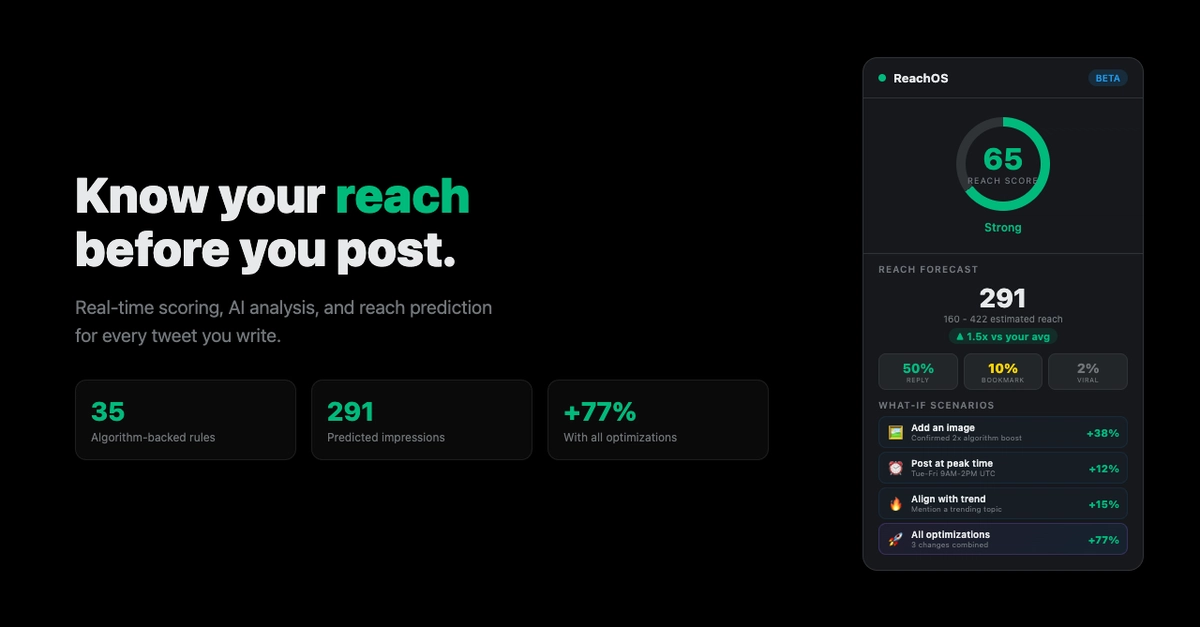
X's Open Algorithm Powers This Free Chrome Extension That Predicts Tweet Reach Live

Open Source
12-Year-Old Drops 2KB PermzPlus Bomb on CASL's Bloat
Open Source