How GPU Batching Turns AI Dreams into Everyday Reality
Picture this: your AI-powered app humming along at 10,000 queries per second, no hiccups, no crashes. That's not sci-fi—it's what smart batching delivers right now.

⚡ Key Takeaways
Worth sharing?
Get the best Developer Tools stories of the week in your inbox — no noise, no spam.
Originally reported by dev.to
Related Stories
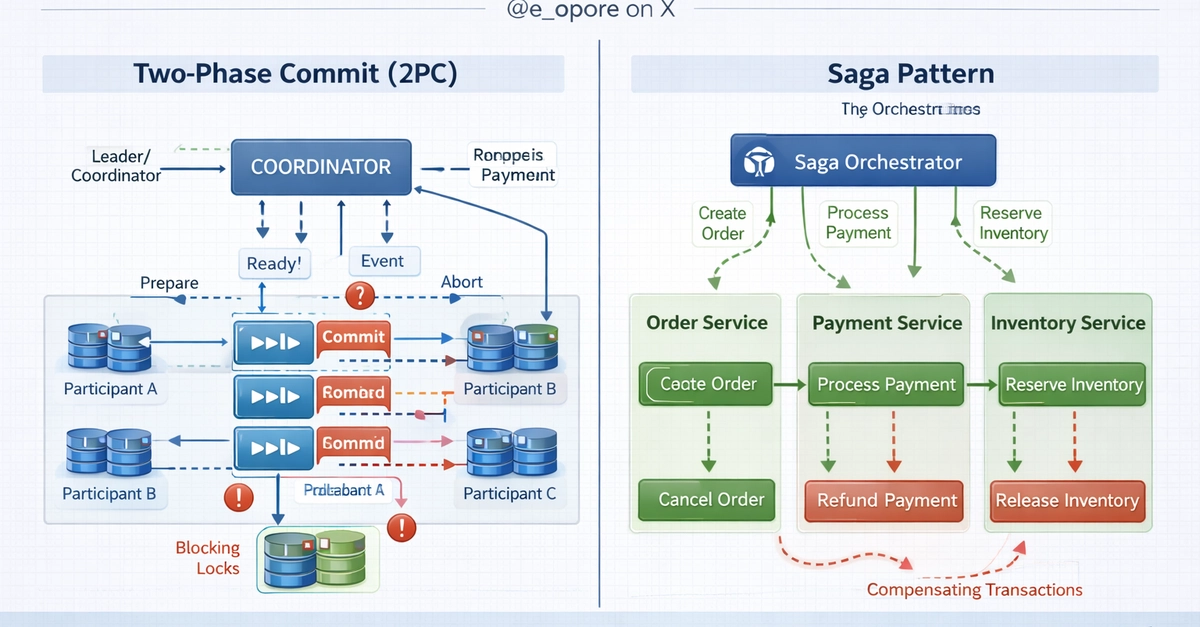
Cloud & Infrastructure
Distributed Transactions: Why 2PC Still Haunts Your Microservices (and Sagas Won't Fully Save You)

Databases & Backend
What If 10 Million Fans Stormed Your Ticket System? Designing Ticketmaster's Backbone
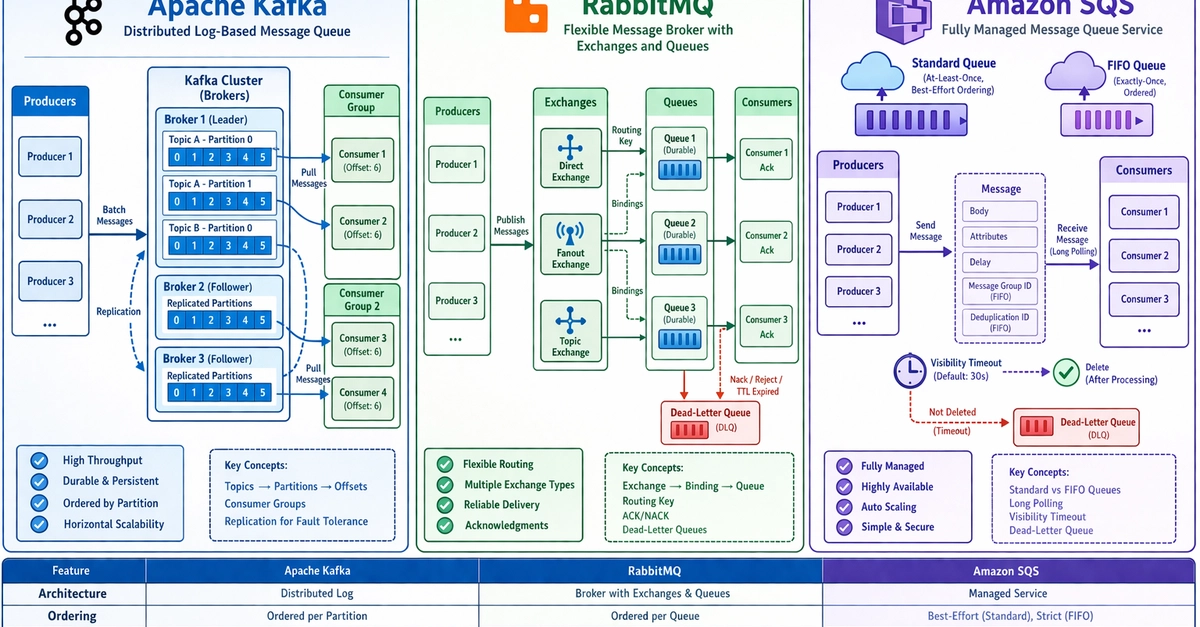
Frontend & Web
Message Queues in System Design: Kafka's Dominance Hides the Real Tradeoffs

AI Dev Tools