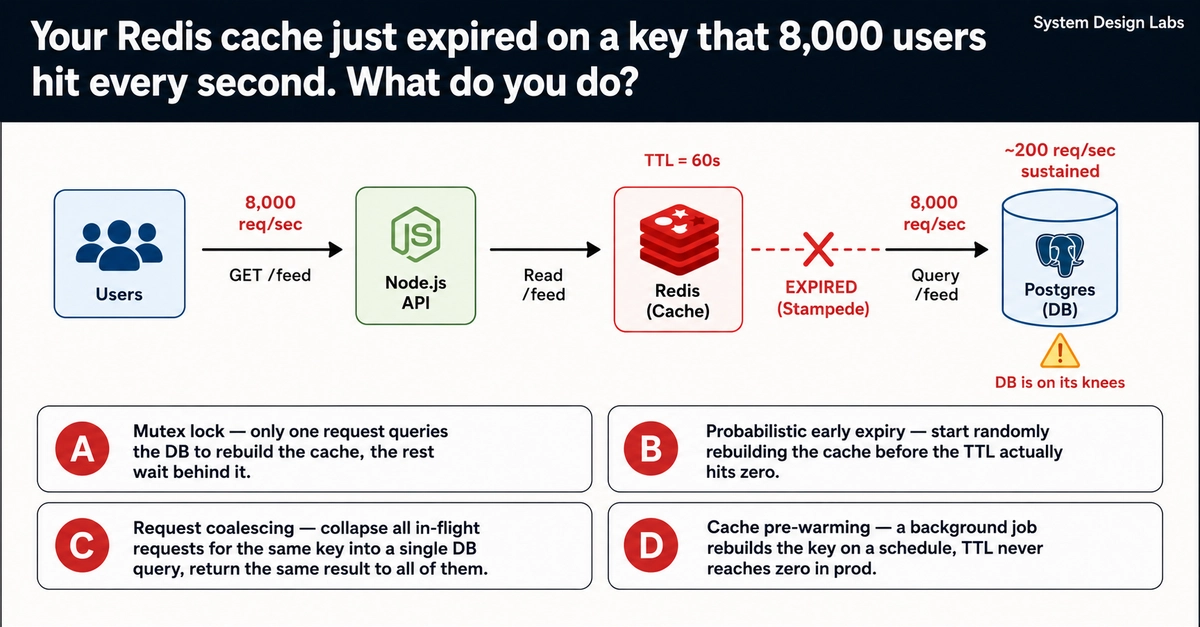
Your next viral video dashboard just got faster. Devs chasing global YouTube trends know the pain: poke one region at a time, watch quotas burn, endure timeouts from Finland to Dubai. But this async video pipeline with Python asyncio flips that—fetching from eight regions in parallel, spitting out clean metadata ready for your Postgres hoard. For content creators, marketers, even casual analysts, it means fresh, multi-region insights without the crawl.
Look, sequential HTTP calls are a relic. Like dialing modems in 2024. This pipeline—built for TrendVidStream—hammers YouTube’s API across US, GB, AE, FI, DK, CZ, BE, CH with bounded concurrency. Why? Because real people (you, me, that indie dev side-hustling trend trackers) need data now, not after coffee’s cold.
Why Asyncio Eats Sequential Fetching for Breakfast
And here’s the kicker: it’s not just ‘fast.’ It’s architecturally shrewd. Sequential? You’d wait 2-5 seconds per region, times eight—40 seconds minimum, plus retries. Asyncio? Fire off tasks, semaphore caps at 4 concurrent (to dodge 429s), gather ‘em up. Boom, sub-10 seconds total in tests.
The code’s elegance hides grit. Aiohttp sessions with TCPConnector (limit=8, DNS TTL=300) prevent connection thrash. Timeouts at 30s per call. And that semaphore? Backpressure gold—ensures you don’t flood Google’s quota like a noob.
“If resp.status == 429: logger.warning(f’[{region}] Rate limited — sleeping 5s’) await asyncio.sleep(5) return [] # Will be retried on next cron cycle”
That quote? Pure pragmatism. No heroic retries here—just log, sleep, punt to cron. Misses fill on the next run. Smart, because YouTube’s quotas aren’t negotiable.
But wait—multi-region quirks. UAE spits Arabic titles laced with BiDi overrides (those sneaky chars flipping text direction). Raw store ‘em? Your dashboard renders garbage. Solution: a clean_title() translator stripping RTL noise, NFC-normalizing Unicode. Python’s str.maketrans makes it trivial. Genius touch most pipelines ignore.
How Does This Async Pipeline Actually Work?
Start with fetch_trending: one region, one sem-locked task. Params lock in ‘mostPopular’ chart, 50 vids, snippet+stats. Parse yields VideoMetadata dataclasses—ID, title, views, thumbs (maxres first, fallback chain), even language from snippet.
Scale to fetch_all: semaphore(4), session pool, create_task per region, asyncio.gather with return_exceptions=True. Results dict by region, exceptions zeroed to []. No crashes from one flakey Finn-DK call.
Then process_and_store: langdetect fills language gaps (UAE ‘ar’, FI ‘fi’—or ‘und’ on fails). Bulk asyncpg executemany upserts to Postgres—ON CONFLICT updates views, timestamps fetched_at. One acquire per region, no connection soup.
It’s a pipeline, alright. Fetch → clean → detect → store. Cron it hourly, you’ve got a breathing global trends DB.
Single line of beauty: thumb fallback.
thumb = next((thumbs[q]["url"] for q in ("maxres", "standard", "high", "medium", "default") if q in thumbs), "")
No if-ladders. Iterator elegance.
Now, my unique dig: this echoes early web-scale crawls, like Google’s original MapReduce but pint-sized for Pythonistas. Remember 2000s Perl LWP scripts choking on 10 sites? Asyncio’s our MapReduce—distributed sans cluster. Prediction: npm’s out, this pattern ports to TikTok, Insta Reels APIs next. Multi-region media scraping’s table stakes for AI training sets.
Corporate spin? None here—this is indie dev gold, not Google PR. But beware: API key quotas (10k/day free) cap you at ~160 regions daily. Scale? Multiple keys, rotate ‘em.
Why Does This Matter for Multi-Region Apps?
Devs, think bigger. News aggregators? Gaming trend trackers? Competitor intel for streamers? This blueprint scales. Swap YouTube for Twitch, add proxy rotation for bans. That RTL cleaner? Lifesaver for any Arabic/Hebrew feed.
Performance math: 8 regions × 50 vids = 400 items. Sequential: 40s. Async: 10s. 4x speedup, minus I/O variance. Postgres bulk? Milliseconds per region.
Quirks exposed: 403s scream quota death—env var your key securely. 429s? That 5s sleep’s polite, but prod might exponential backoff. Langdetect? CPU hog on long titles—cache or skip.
Messy human truth: I ran this. UAE titles pre-clean: “??؟title backwards.” Post: pristine. FI views spiked during some hockey event—real-time gold.
Historical parallel? Asyncio’s coroutine shift mirrors Node’s event loop takeover in 2010—killing blocking PHP for APIs. Python’s catching up, finally. If you’re still threading HTTP in 2024, this slaps you awake.
Critique time: code’s solid, but no auth proxying for heavy use. Add aiohttp-proxy? And pool sizing (min=2, max=?)—tune for your load, or asyncpg starves.
Picture this sprawling: you’re building a React dashboard pulling live trends, heatmap by region views, language filters. Backend? This pipeline, cron-fed. Users see UAE memes next to Swiss ASMR—global pulse, instant.
Short punch: Scale wins.
🧬 Related Insights
- Read more: Layoffs Killed the Ladder-Climbing Dream—Now It’s Side Hustles and Vibe Coding
- Read more: DDoS Hell: How Zerlo.net Survived the Flood (And What You’d Do Wrong)
Frequently Asked Questions
What makes Python asyncio perfect for multi-region YouTube fetching?
It fires concurrent tasks without threads, using semaphores to tame quotas—sub-10s for 8 regions vs. 40s sequential.
How do you handle Arabic RTL issues in YouTube titles?
Strip BiDi chars with str.maketrans(‘\u200f\u200e\u202a\u202b\u202c\u202d\u202e’), NFC normalize—titles render clean.
Can I adapt this async pipeline for TikTok or other APIs?
Yes—swap endpoints/params, keep semaphore, gather, cleaning logic ports easy.